Java 读取PDF中的文本和图片
2020-12-13 14:25
标签:install PDF文档 ati 下载 out images ofo group extract 使用工具:Free Spire.PDF for Java(免费版) 方法2: 可通过maven仓库安装导入,可参考导入方法。 Java代码示例 文本读取结果: 【示例2】读取PDF中的图片 图片读取结果: (本文完) Java 读取PDF中的文本和图片 标签:install PDF文档 ati 下载 out images ofo group extract 原文地址:https://blog.51cto.com/eiceblue/2439713
Jar文件获取导入:
方法1:通过官网下载jar文件包。下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar文件导入java程序。导入后如下图:
【示例1】读取PDF中的文本import com.spire.pdf.*;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractText {
public static void main(String[]args) throws Exception {
//加载测试文档
PdfDocument pdf = new PdfDocument("sample.pdf");
//实例化StringBuilder类
StringBuilder sb = new StringBuilder();
//定义一个int型变量
int index = 0;
//遍历PDF文档中每页
PdfPageBase page;
for (int i= 0; i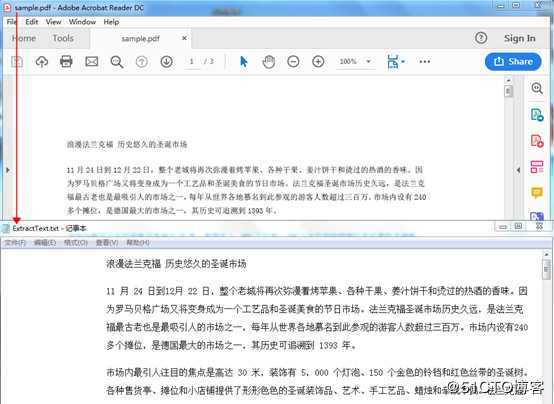
import com.spire.pdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
public class ExtractImg {
public static void main(String[] args) throws Exception{
//加载测试文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("test.pdf");
//定义一个int型变量
int index = 0;
//遍历PDF每一页
for (int i= 0;i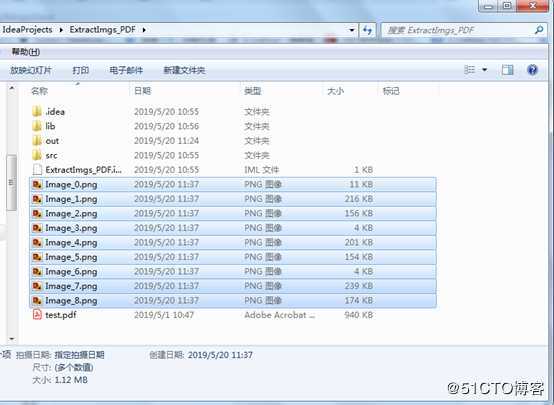
上一篇:c#接口
下一篇:wpf的学习日志(二)