windows 8.0上eclipse 4.4.0 配置centos 6.5 上的hadoop2.2.0开发环境
2020-12-13 16:30
标签:des style blog http io color ar os java
windows 8.0上eclipse 4.4.0 配置centos 6.5 上的hadoop2.2.0开发环境 标签:des style blog http io color ar os java 原文地址:http://blog.csdn.net/shijiebei2009/article/details/40925575

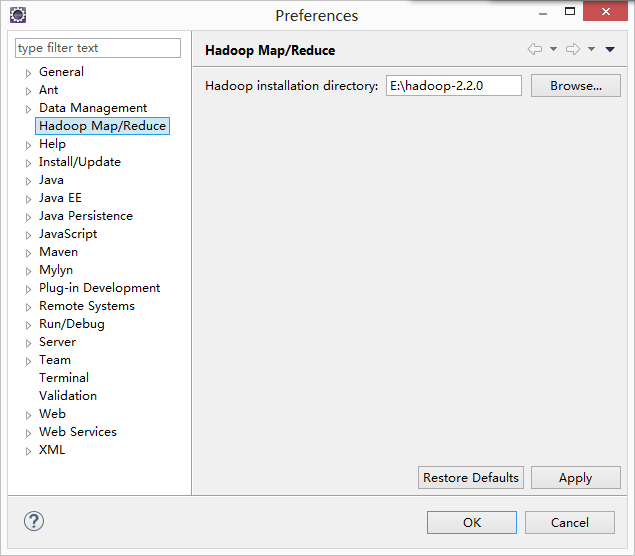 ,这里面的hadoop
installation directory并不是你windows上装的hadoop目录,而仅仅是你在centos上编译好的源码,在windows上的解压路径而已,该路径仅仅是用于在创建MapReduce Project能从这个地方自动引入MapReduce所需要的jar
,这里面的hadoop
installation directory并不是你windows上装的hadoop目录,而仅仅是你在centos上编译好的源码,在windows上的解压路径而已,该路径仅仅是用于在创建MapReduce Project能从这个地方自动引入MapReduce所需要的jar
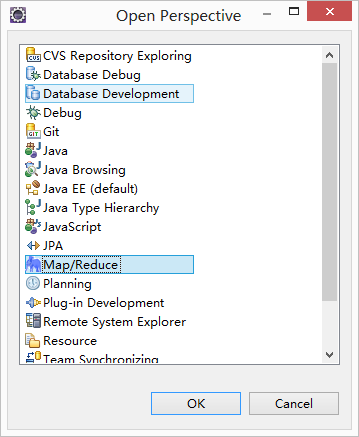

 ,右击选择,New
Hadoop location,这个时候会出现
,右击选择,New
Hadoop location,这个时候会出现
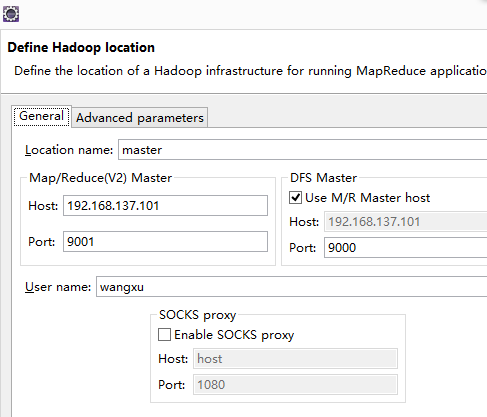 Map/Reduce(V2)中的配置对应于mapred-site.xml中的端口配置,DFS
Master中的配置对应于core-site.xml中的端口配置,配置完成之后finish即可,这个时候可以查看
Map/Reduce(V2)中的配置对应于mapred-site.xml中的端口配置,DFS
Master中的配置对应于core-site.xml中的端口配置,配置完成之后finish即可,这个时候可以查看
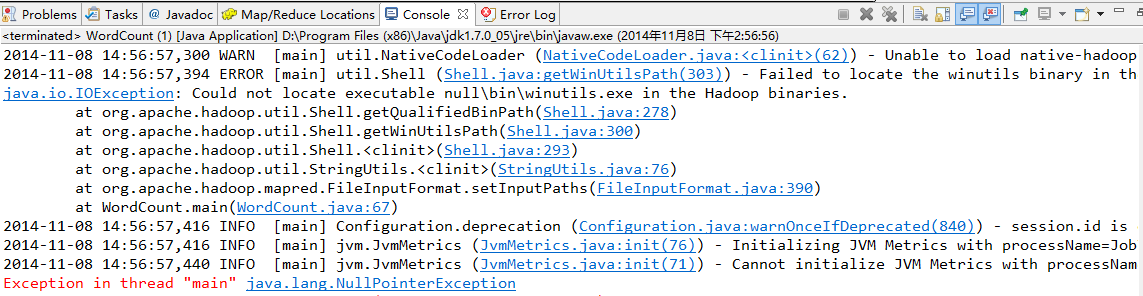 ,要解决这个问题,你必须要完成如下几个步骤,在windows上配置HADOOP_HOME,然后将%HADOOP_HOME%\bin加入到path之中,然后去https://github.com/srccodes/hadoop-common-2.2.0-bin下载一个,下载之后将这个bin目录里面的东西全部拷贝到你自己windows上的HADOOP的bin目录下,覆盖即可,同时把hadoop.dll加到C盘下的system32中,如果这些都完成之后还是碰到:Exception
in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z,那么就检查一下你的JDK,有可能是32位的JDK导致的,需要下载64位JDK安装,并且在eclipse将jre环境配置为你新安装的64位JRE环境
,要解决这个问题,你必须要完成如下几个步骤,在windows上配置HADOOP_HOME,然后将%HADOOP_HOME%\bin加入到path之中,然后去https://github.com/srccodes/hadoop-common-2.2.0-bin下载一个,下载之后将这个bin目录里面的东西全部拷贝到你自己windows上的HADOOP的bin目录下,覆盖即可,同时把hadoop.dll加到C盘下的system32中,如果这些都完成之后还是碰到:Exception
in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z,那么就检查一下你的JDK,有可能是32位的JDK导致的,需要下载64位JDK安装,并且在eclipse将jre环境配置为你新安装的64位JRE环境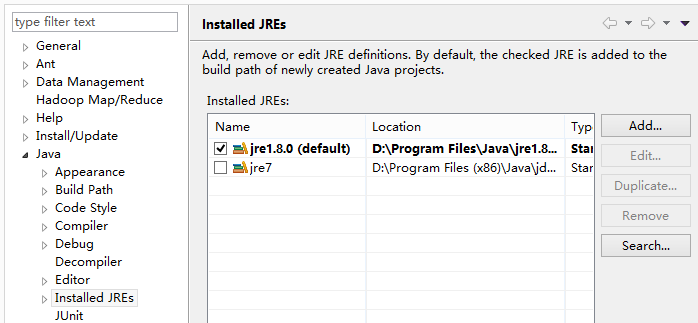 。
。 如我的jre1.8是64位,jre7是32位,如果这里面没有,你直接add即可,选中你的64位jre环境之后,就会出现了。
如我的jre1.8是64位,jre7是32位,如果这里面没有,你直接add即可,选中你的64位jre环境之后,就会出现了。
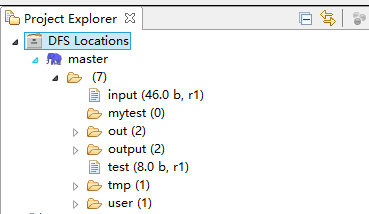
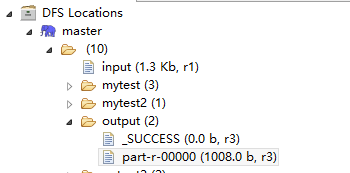
至此,程序终于运行成功,刷新一下你的DFS即可,看到输出结果
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper

文章标题:windows 8.0上eclipse 4.4.0 配置centos 6.5 上的hadoop2.2.0开发环境
文章链接:http://soscw.com/essay/36225.html