谈谈雪花算法的使用
2021-05-13 21:29
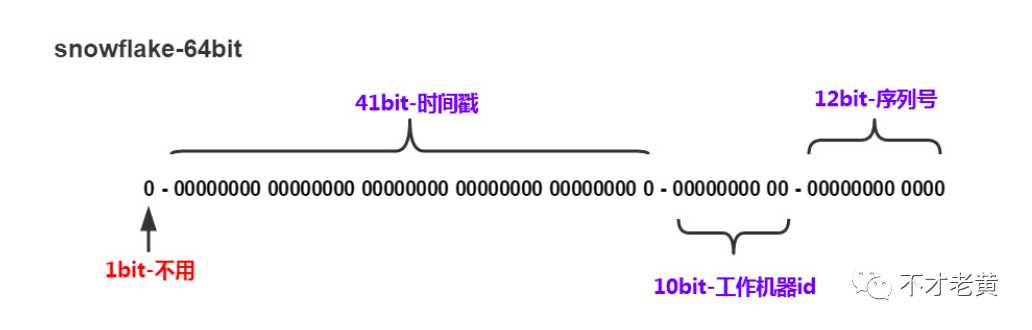
标签:reading 需要 long 临时 src 随机数 arch sys throw 618来临之际,为了应对一些突发流量,购买了两台一个月的ECS用来临时对部分项目扩容。其中一个项目有用到雪花算法来生成Id,这个还是挺OK的。 不过发现要在配置文件中手动配置机器码!!配置的时候还要先知道目前配置了那些,这样才可以避免重复。 经过了解,除了会有单机单实例的情况,还会有单机多实例的情况。 这个要人工配置,是徒增工作量的,有点让人难以接受。 针对这个,老黄就做了一点调整,让这个机器码自动生成。 关于雪花算法,大部分文章都可以看到这个图。这个图很好的诠释了雪花算法生成Id的几个重要组成部分,这里也不展开具体介绍了。 时间戳,工作机器Id,序列号这些位数是可以根据自己的业务场景来进来调整的。 10bit工作机器Id,其实就是上面说到的机器码,雪花算法内部并没有做任何处理,而是交由业务方自己定义,所以业务方需要自己保证这个的唯一性。 大部分情况,会把它分为5bit数据中心标识和5bit机器Id。这样的话可以支持32个数据中心和32个机器Id。 换句话说就是,一个业务可以在一个数据中心部署32个实例,最多部署的32个数据中心。正常来说,大部分项目,都不会需要部署这么多实例。。。 考虑到内网的IP段基本上是固定的,同一个应用基本上也会在连续的IP上面部署。 所以这里老黄最后采用的是本地IP地址取余做为机器Id,机器的HostName取余做为默认的数据中心Id。 下面来看看具体的实现。 自动获取机器Id和数据中心Id。 生成器的构造函数 这里的数据中心可以让使用方自己定义,默认-1的话,会根据HostName去生成一个。 这里给一个自定义的可选标识,主要还是考虑到了单机多实例,即一个IP上面部署多个实例。 虽然这个时候还是要考虑人工配置,不过已经从多机变成单机了,也算是一点简化。毕竟大部分情况下也不会建议在同一个机器部署多个一样的项目。 默认情况下的使用,IdGenerator对象要全局唯一,做成单例即可。 下面运行多个容器来模拟。 可以看到机器Id和数据中心Id都是没有重复的。 在运行一次。 也是同样的。 目前这种做法在应用实例少,机器数量少的情况下是基本可以满足使用要求的了。老黄公司目前也就不到30台服务器,所以怎么都是够用的。 但是依靠IP和HostName,随着实例或机器的数量增多,没有办法保证它们取余算出来的一定是唯一的。 在这种情况下就需要考虑引用第三方存储(Redis或数据库)来保证这个的唯一性了。 下面是本文的示例代码: SnowflakeDemo 谈谈雪花算法的使用 标签:reading 需要 long 临时 src 随机数 arch sys throw 原文地址:https://www.cnblogs.com/catcher1994/p/13128922.html背景
雪花算法基础
简单实现
/// public IdGenerator(long datacenterId = -1)
{
if (datacenterId == -1)
{
// default
datacenterId = GetDatacenterId();
}
if (datacenterId > MaxDatacenterId || datacenterId IdGenerator generator = new IdGenerator();
Parallel.For(0, 20, x =>
{
Console.WriteLine(generator.NextId());
});
Console.WriteLine("Hello World!");
System.Threading.Thread.Sleep(1000 * 60);
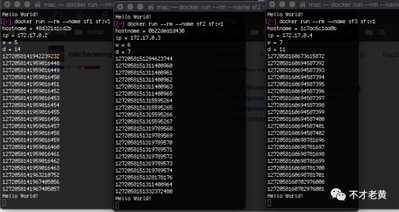
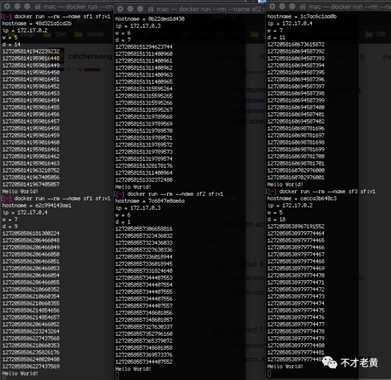
不足与展望