Java实现网络爬虫-Java入门|Java基础课程
2021-06-29 20:04
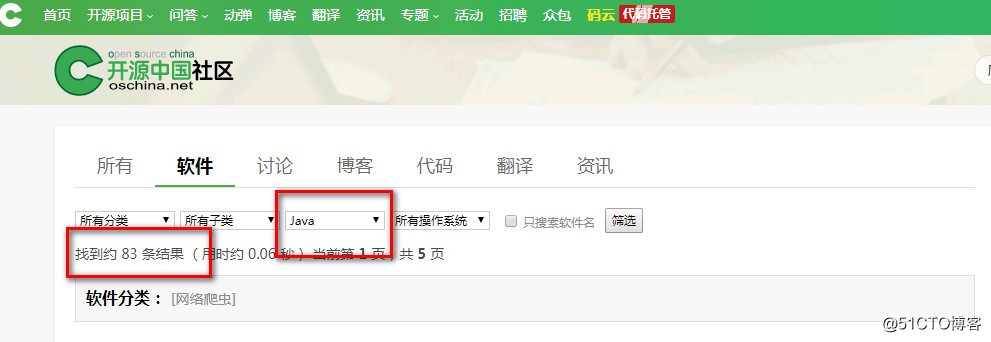
标签:row entry 2.3 ddp settime override ade getc mini 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚 本。 网络爬虫是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到 在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有 的网页都抓取完为止。 如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。 所以要想抓取网络上的数据,不仅需要爬虫程序还需要一个可以接受”爬虫“发回的数据并进行处理过滤的服务 器,爬虫抓取的数据量越大,对服务器的性能要求则越高。 网络爬虫是做什么的? 他的主要工作就是 跟据指定的url地址 去发送请求,获得响应, 然后解析响应 , 一方面从 响应中查找出想要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续查找需要的 数据和继续解析出新的URL路径 . 通过上面的流程图 能大概了解到 网络爬虫 干了哪些活 ,根据这些 也就能设计出一个简单的网络爬虫出来. 一个简单的爬虫 必需的功能: 好了,我们上面已经将在代码中需要获取的关键信息的XPath表达式都找到了,接下来就可以正式写代码来实现了 代码实现部分采用webmagic框架,因为这样比使用基本的的Java网络编程要简单得多 Demo.java 在开源社区搜索java爬虫框架 : 共有83种 webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一 个爬虫 webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久 化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能 webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内 容的提取,支持多个选择器链式调用 注:官方中文文档: 可以使用maven构建依赖,如: 当然,也可以自行下载jar包,其地址是: 一般来说,如果我们需要抓取的目标数据不是通过ajax异步加载进来的话,那么我们都可以在页面的HTML源代码中的某个位置找到我们所需要的数据 注:如果数据是通过异步加载到页面中,那么一般有以下两种方式来获取数据: 下面我用我们的官网将跟大家一起来分析下如何实现这样的一个爬虫: 从上图可以看出,我们是可以直观地从首页的HTML源代码中找到我们所需要的标题、内容、图片链接等信息的。那么接下来我们可以通过哪种方式将这些目标数据提取出来呢? 其实,关于页面元素的抽取webmagic框架主要支持以下三种方式: 当然,选择哪种方式来抽取数据需要根据具体页面具体分析。在这个例子中,很显然使用XPath来抽取数据是最方便的 因此,接下来我就直接给出我们需要抓取的数据的所在XPath路径了: 注:“//”表示从相对路径开始,最前面以“/”开始则表示从页面的跟路经开始;后面的两个/之间的内容表示一个元素,中括号里面的内容则表示该元素的执行属性,如:h1[@class=’entry-title’] 表示:拥有class属性为“entry-title”的h1元素 使用webmagic抽取页面数据时需要自定义一个类实现PageProcessor接口。 这个实现了PageProcessor接口的类主要功能为以下三步曲: Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置 注:更多详细参数介绍可以参考这里的官方文档: Demo.java 对于抽取逻辑比较复杂的爬虫我们通常像上面那样实现PageProcessor接口自己来写页面元素的抽取逻辑。但是对于抽取逻辑比较简单的爬虫来说,这时我们可以选择在实体类上添加注解的方式来构建轻量型的爬虫 从上面的代码可以看出,这里除了添加了几个注解之外,这个实体类就是一个普通的POJO,没有依赖其他任何东西。关于上面使用到的几个注解的大概含义是: 虽然在PageProcessor中我们可以实现数据的持久化(PS:基于注解的爬虫可以实现AfterExtractor 接口达到类似的目的),将爬虫抓取到的数据保存到文件、数据库、缓存等地方。但是很显然PageProcessor或者实体类主要负责的是页面元素的抽取工作,因此更好的处理方式是在另一个地方单独做数据的持久化。这个地方也就是——Pipeline 为了实现数据的持久化,我们通常需要实现Pipeline 或者PageModelPipeline接口。普通爬虫使用前一个接口,基于注解的爬虫则使用后一个接口 基于注解的爬虫,其启动类就不是Spider了,而是OOSpider类了,当然二者的使用方式类似。示例代码如下: jsoup 是一款 Java 的HTML 解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于JQuery的操作方法来取出和操作数据 Jsoup是Java世界的一款HTML解析工具,它支持用CSS Selector方式选择DOM元素,也可过滤HTML文本,防止XSS×××。 下载Jsoup 查看官方提供的手册: Jsoup是Java世界用作html解析和过滤的不二之选。支持将html解析为DOM树、支持CSS Selector形式选择、支持html过滤,本身还附带了一个Http下载器。 Jsoup的代码相当简洁,Jsoup总共53个类,且没有任何第三方包的依赖,对比最终发行包9.8M的SAXON,实在算得上是短小精悍了。 Jsoup的入口是 这里用 Jsoup使用了自己的一套DOM代码体系,这里的Elements、Element等虽然名字和概念都与Java XML API 但是正因为如此,才使得Jsoup可以抛弃xml里一些繁琐的API,使得代码更加简单。 欢迎进×××流学习,更多不定期福利、免费课程等你来~ QQ群号:560819979 敲门砖(验证信息):浪淘沙 Java实现网络爬虫-Java入门|Java基础课程 标签:row entry 2.3 ddp settime override ade getc mini 原文地址:http://blog.51cto.com/13477015/2174525
1. 网络爬虫
1.1. 名称
1.2. 简述
2. 流程

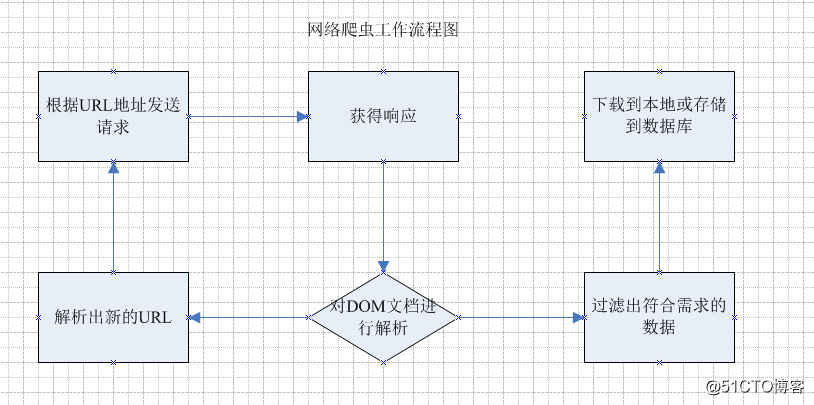
2.1. 关注点
3. 分类
4. 思路分析

首先观察我们爬虫的起始页面是:http://www.wanho.net/a/jyxb/

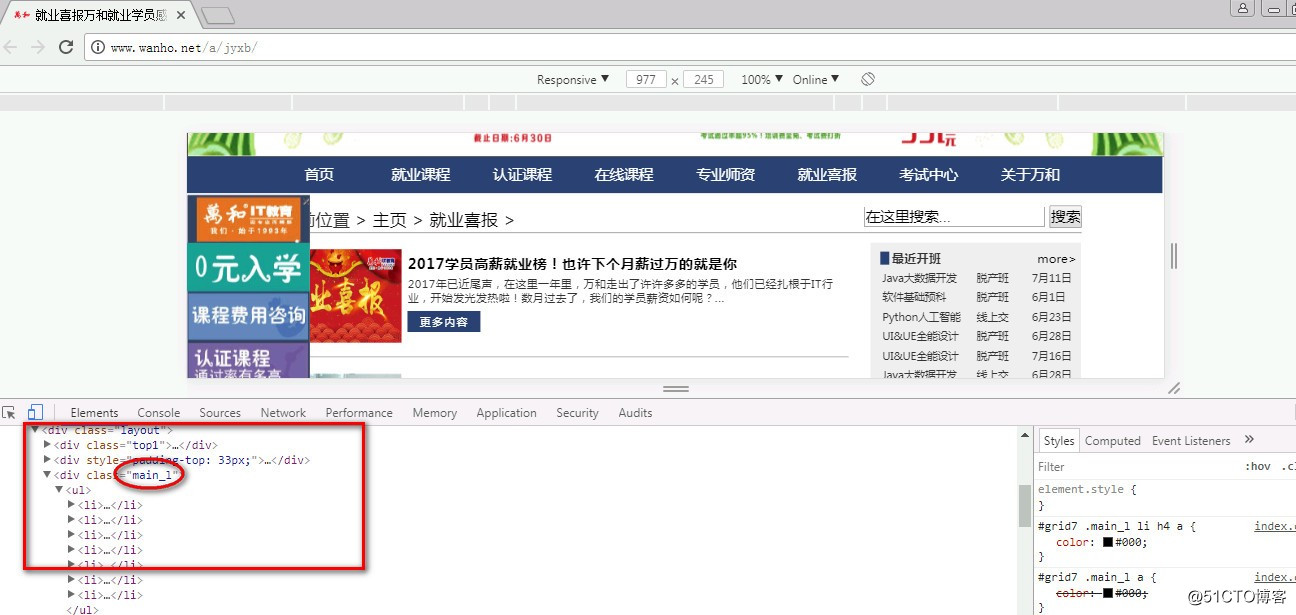
所有的喜报信息的URL用XPath表达式来表示就是://div[@class=‘main_l‘]/ul/li

相关数据
//div[@class=‘content‘]/h4/a/text()
//div[@class=‘content‘]/p/text()
//a/img/@src
5. 代码实现
注:关于webmagic框架可以看一下面讲义5.1. 代码结构

5.2. 程序入口
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}5.3. 爬取过程
package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List5.4. 结果保存
package net.wanho.wanhosite;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.Vector;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public class WanhoPipeline implements Pipeline {
@Override
public void process(ResultItems resultItems, Task arg1) {
// 获取抓取过程中保存的数据
Vector voLst =resultItems.get("e_list");
// 持久到文件中
PrintWriter pw=null;
try {
pw = new PrintWriter(new FileWriter("wanho.txt",true));
for(ArticleVo vo :voLst){
pw.println(vo);
pw.flush();
saveImg(vo.getImg());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
pw.close();
}
}
private void saveImg(String img) {
String imgUrl = "http://www.wanho.net"+img;
InputStream is = null;
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
URL url = new URL(imgUrl);
URLConnection uc = url.openConnection();
is = uc.getInputStream();
bis = new BufferedInputStream(is);
File photoFile = new File("photo");
if(!photoFile.exists()){
photoFile.mkdirs();
}
String imgName = img.substring(img.lastIndexOf("/")+1);
File saveFile = new File(photoFile,imgName);
bos = new BufferedOutputStream(new FileOutputStream(saveFile));
byte[] bs = new byte[1024];
int len;
while((len=bis.read(bs))!=-1){
bos.write(bs, 0, len);
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}5.5. 模型对象
package net.wanho.wanhosite;
public class ArticleVo {
private String title;
private String content;
private String img;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public ArticleVo(String title, String content, String img) {
super();
this.title = title;
this.content = content;
this.img = img;
}
@Override
public String toString() {
return "Article [title=" + title + ", content=" + content + ", img=" + img + "]";
}
}6. webmagic框架

我们使用的是

6.1. 简介
6.2. 实现
6.2.1. jar包下载:
6.2.2. 观察目标数据所处的HTML页面位置:
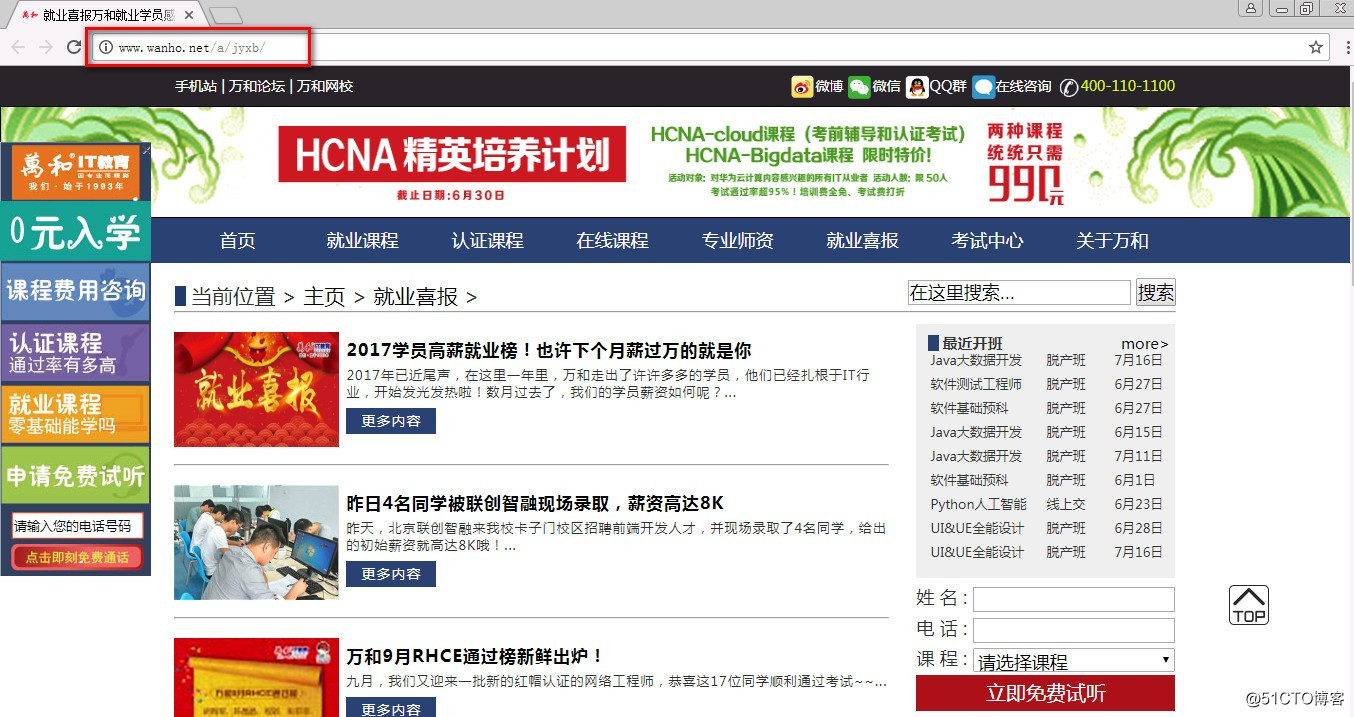
首先观察我们爬虫的起始页面是:http://www.wanho.net/a/jyxb/
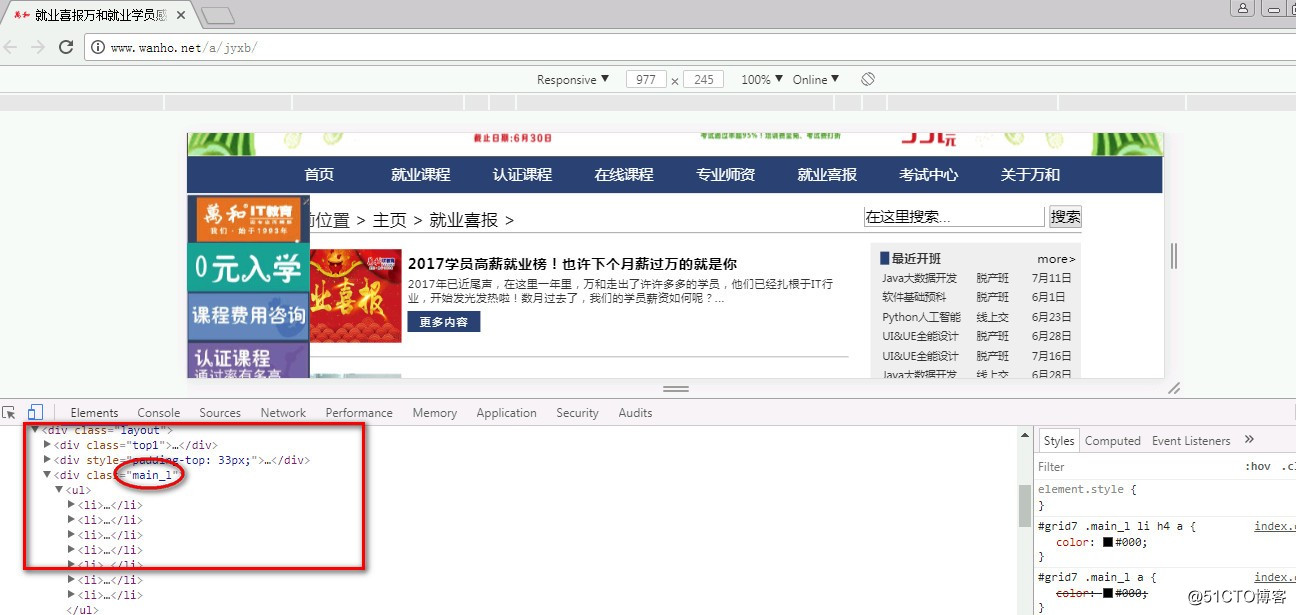

//div[@class=‘main_l‘]/ul/li
//div[@class=‘content‘]/h4/a/text()
//div[@class=‘content‘]/p/text()
//a/img/@src
6.2.3. 页面数据抽取:
package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List6.2.4. 爬虫的启动与停止:
package net.wanho.wanhosite;
import us.codecraft.webmagic.Spider;
public class Demo {
/**
* 程序的入口
*/
public static void main(String[] args) {
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
//第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
//启动三个线程
.thread(3)
//开始
.run();
}
}6.3. 基于注解
6.3.1. 实体类的构造:
package net.wanho.wanhosite;
import java.util.List;
import us.codecraft.webmagic.model.annotation.ExtractBy;
import us.codecraft.webmagic.model.annotation.HelpUrl;
import us.codecraft.webmagic.model.annotation.TargetUrl;
@TargetUrl(value="http://www.wanho.net/a/jyxb/\\w+.html")
@HelpUrl(value="http://www.wanho.net/a/jyxb/")
public class ArticleExtra{
/**
* 标题
*/
@ExtractBy(value="//div[@class=‘content‘]/h4/a/text()",notNull=true)
private List
6.3.2. 数据的持久化:
package net.wanho.wanhosite;
import java.util.List;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.model.OOSpider;
import us.codecraft.webmagic.pipeline.PageModelPipeline;
/**
* 自定义Pipeline以实现数据的保存
*
*/
public class WanhoPipeline2 implements PageModelPipeline {
public void process(ArticleExtra articleExtra, Task task) {
List6.3.3. 爬虫的启动:
public static void main(String[] args) {
Site site = Site.me().setTimeOut(10000).setRetryTimes(3).setSleepTime(1000).setCharset("UTF-8");
OOSpider.create(site,new WanhoPipeline2 (), ArticleExtra.class)
.addUrl("http://www.wanho.net/a/jyxb")
.thread(5)
.run();
}7. Jsoup介绍
7.1. 概述
jsoup
├── examples #样例,包括一个将html转为纯文本和一个抽取所有链接地址的例子。
├── helper #一些工具类,包括读取数据、处理连接以及字符串转换的工具
├── nodes #DOM节点定义
├── parser #解析html并转换为DOM树
├── safety #安全相关,包括白名单及html过滤
└── select #选择器,支持CSS Selector以及NodeVisitor格式的遍历7.2. 功能
7.3. 使用
Jsoup类。examples包里提供了两个例子,解析html后,分别用CSS Selector以及NodeVisitor来操作Dom元素。ListLinks里的例子来说明如何调用Jsoup:package net.wanho.blog;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
*
* 使用JSoup 解析网页,语法使用 JS,css,Jquery 选择器语法,方便易懂
* Jsoup教程网:http://www.open-open.com/jsoup/
*
*/
public class JsoupDemo {
public static void main(String[] args) throws IOException {
String url = "https://www.oschina.net/news";
Document document = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/30.0").get();
Elements elements = document.select("#all-news div ");
Elements es = document.select("#all-news div div ");
for (Element e : es) {
System.out.println(e.select("a.title>span").text());
System.out.println(e.select("div").text());
System.out.println("-----------");
}
System.out.println(elements.size());
}
}org.w3c.dom类似,但并没有代码层面的关系。就是说你想用XML的一套API来操作Jsoup的结果是办不到的,8. XPath语法介绍