thinkphp 抓取网站的内容并且保存到本地的实例详解
2018-09-07 14:55
阅读:411
thinkphp 抓取网站的内容并且保存到本地的实例详解
我需要写这么一个例子,到电子课本网下载一本电子书。
电子课本网的电子书,是把书的每一页当成一个图片,然后一本书就是有很多张图片,我需要批量的进行下载图片操作。
下面是代码部分:
public function download() { $http = new \Org\Net\Http(); $url_pref = 下载完成; }
我这里是以人教版地理七年级地理上册为例子
网页是从001.htm开始,然后数字一直加
每个网页里面都有一张图,就是对应课本的内容,以图片的形式展示课本内容
我的代码是做了一个循环,从第一页开始抓,一直抓到找不到网页里的图片为止
抓到网页的内容后,把网页里面的图片抓取到本地服务器
抓取后的实际效果:
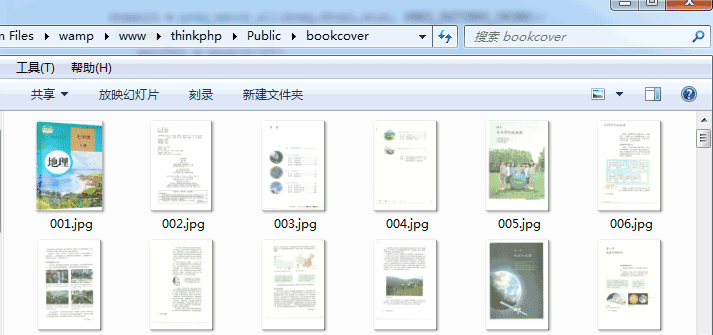
以上就是thinkphp 抓取网站的内容并且保存到本地的实例详解,如有疑问请留言或者到本站社区交流讨论,感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
文章来自:搜素材网的编程语言模块,转载请注明文章出处。
文章标题:thinkphp 抓取网站的内容并且保存到本地的实例详解
文章链接:http://soscw.com/index.php/essay/13975.html
文章标题:thinkphp 抓取网站的内容并且保存到本地的实例详解
文章链接:http://soscw.com/index.php/essay/13975.html
评论
亲,登录后才可以留言!