python实现抖音视频批量下载
2018-10-15 18:10
阅读:1171
本文实例为大家分享了python实现抖音视频批量下载的具体代码,供大家参考,具体内容如下
这里就拿最近很火的抖音视频为例,利用API来实现用户抖音视频的批量下载
主要用到的模块有
1、requests模块;
2、bs4模块;
import requests import bs4 import os import json import re import sys import time from contextlib import closing requests.packages.urllib3.disable_warnings() class Spider(): def __init__(self): self.headers = { User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36 } print([INFO]:Douyin App Video downloader...) print([Version]: V1.0) print([Author]: Charles) # 外部调用运行 def run(self): user_id = input(Enter the ID:) try: int(user_id) except: print([Error]:ID error...) return video_names, video_urls, nickname = self._parse_userID(user_id) if nickname not in os.listdir(): os.mkdir(nickname) print([INFO]:Number of Videos <%s> % len(video_urls)) for num in range(len(video_names)): print([INFO]:Parsing <No.%d> <Url:%s> % (num+1, video_urls[num])) temp = video_names[num].replace(\\, ) video_name = temp.replace(/, ) self._downloader(video_urls[num], os.path.join(nickname, video_name)) print(\n) print([INFO]:All Done...) # 视频下载 def _downloader(self, video_url, path): size = 0 download_url = self._get_download_url(video_url) with closing(requests.get(download_url, headers=self.headers, stream=True, verify=False)) as response: chunk_size = 1024 content_size = int(response.headers[content-length]) if response.status_code == 200: sys.stdout.write([File Size]: %0.2f MB\n % (content_size/chunk_size/1024)) with open(path, wb) as f: for data in response.iter_content(chunk_size=chunk_size): f.write(data) size += len(data) f.flush() sys.stdout.write([Progress]: %0.2f%% % float(size/content_size*100) + \r) sys.stdout.flush() # 获得视频下载地址 def _get_download_url(self, video_url): res = requests.get(url=video_url, verify=False) soup = bs4.BeautifulSoup(res.text, lxml) script = soup.find_all(script)[-1] video_url_js = re.findall(var data = \[(.+)\];, str(script))[0] html = json.loads(video_url_js) return html[video][play_addr][url_list][0] # 通过user_id获取该用户发布的所有视频 def _parse_userID(self, user_id): video_names = [] video_urls = [] unique_id = while unique_id != user_id: search_url = 抖音-原创音乐短视频社区 == share_desc: video_names.append(str(i) + .mp4) i += 1 else: video_names.append(share_desc + .mp4) video_urls.append(each[share_info][share_url]) return video_names, video_urls, nickname if __name__ == __main__: sp = Spider() sp.run()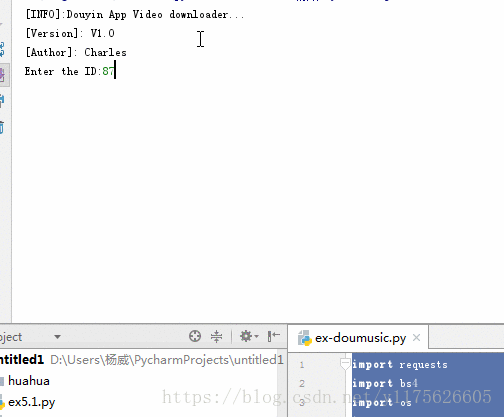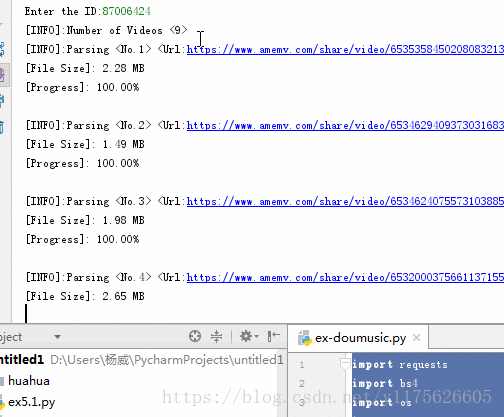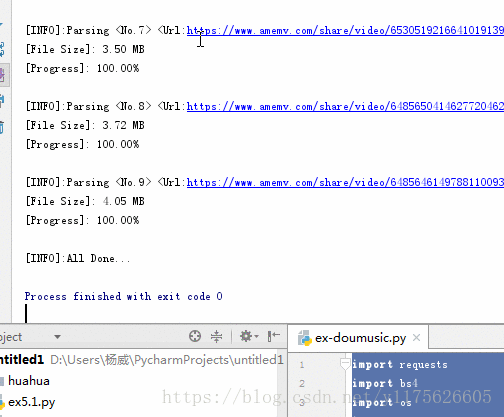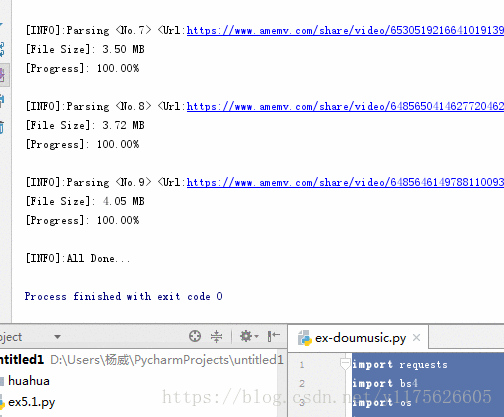
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
评论
亲,登录后才可以留言!