进击的 Kubernetes 调度系统(二):支持批任务的 Coscheduling/Gang sc
2021-01-20 15:13
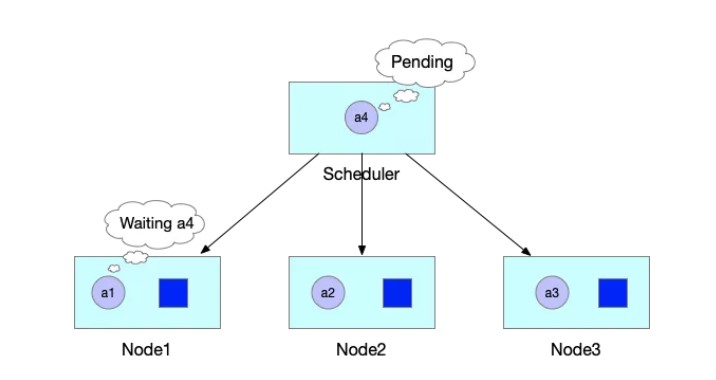
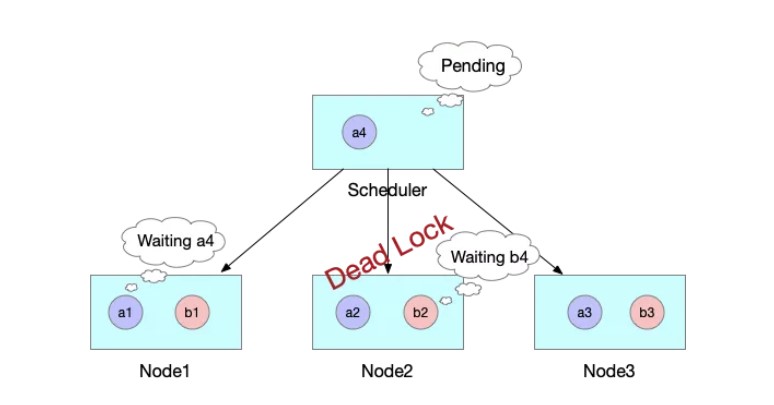
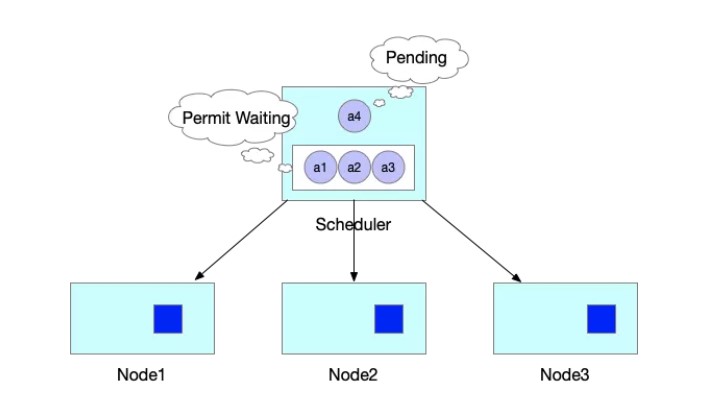
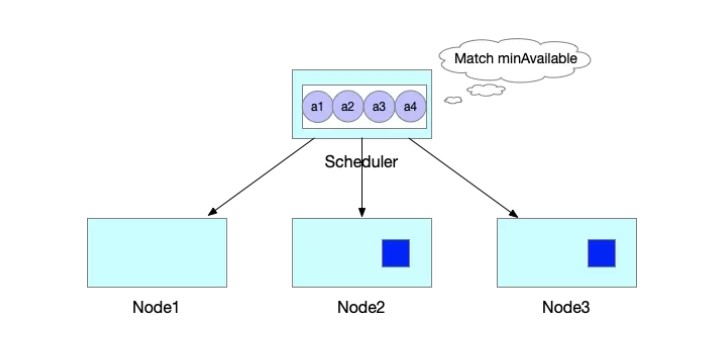
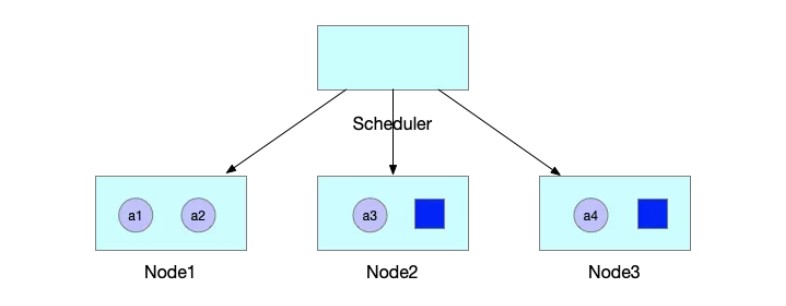
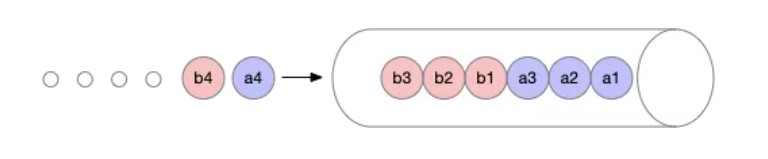
标签:png 官方 lte 机器 内容 自增 运行时 执行 VID 作者 | 王庆璨(阿里云技术专家)、张凯(阿里云高级技术专家) 导读:阿里云容器服务团队结合多年 Kubernetes 产品与客户支持经验,对 Kube-scheduler 进行了大量优化和扩展,逐步使其在不同场景下依然能稳定、高效地调度各种类型的复杂工作负载。《进击的 Kubernetes 调度系统》系列文章将把我们的经验、技术思考和实现细节全面地展现给 Kubernetes 用户和开发者,期望帮助大家更好地了解 Kubernetes 调度系统的强大能力和未来发展方向。本文为该系列文章的第二篇。 什么是 Coscheduling 和 Gang scheduling。Wikipedia 对 Coscheduling 的定义是“在并发系统中将多个相关联的进程调度到不同处理器上同时运行的策略”。在 Coscheduling 的场景中,最主要的原则是保证所有相关联的进程能够同时启动。防止部分进程的异常,导致整个关联进程组的阻塞。这种导致阻塞的部分异常进程,称之为“碎片(fragement)”。 在 Coscheduling 的具体实现过程中,根据是否允许“碎片”存在,可以细分为 Explicit Coscheduling,Local Coscheduling 和 Implicit Coscheduling。 其中 Explicit Coscheduling 就是大家常听到的 Gang Scheduling。Gang Scheduling 要求完全不允许有“碎片”存在, 也就是“All or Nothing”。 我们将上述定义的概念对应到 Kubernetes 中,就可以理解 Kubernetes 调度系统支持批任务 Coscheduling 的含义了。 一个批任务(关联进程组)包括了 N 个 Pod(进程),Kubernetes 调度器负责将这 N 个 Pod 调度到 M 个节点(处理器)上同时运行。如果这个批任务需要部分 Pod 同时启动即可运行,我们称需启动 Pod 的最小数量为 min-available。特别地,当 min-available=N 时,批任务要求满足 Gang Scheduling。 Kubernetes 目前已经广泛的应用于在线服务编排,为了提升集群的的利用率和运行效率,我们希望将 Kubernetes 作为一个统一的管理平台来管理在线服务和离线作业。默认的调度器是以 Pod 为调度单元进行依次调度,不会考虑 Pod 之间的相互关系。但是很多数据计算类的离线作业具有组合调度的特点,即要求所有的子任务都能够成功创建后,整个作业才能正常运行。如果只有部分子任务启动的话,启动的子任务将持续等待剩余的子任务被调度。这正是 Gang Scheduling 的场景。 如下图所示,JobA 需要 4 个 Pod 同时启动,才能正常运行。Kube-scheduler 依次调度 3 个 Pod 并创建成功。到第 4 个 Pod 时,集群资源不足,则 JobA 的 3 个 Pod 处于空等的状态。但是它们已经占用了部分资源,如果第 4 个 Pod 不能及时启动的话,整个 JobA 无法成功运行,更糟糕的是导致集群资源浪费。 如果出现更坏的情况的话,如下图所示,集群其他的资源刚好被 JobB 的 3 个 Pod 所占用,同时在等待 JobB 的第 4 个 Pod 创建,此时整个集群就出现了死锁。 社区目前有 Kube-batch 以及基于 Kube-batch 衍生的 Volcano 2 个项目来解决上文中提到的痛点。实现的方式是通过开发新的调度器将 Scheduler 中的调度单元从 Pod 修改为 PodGroup,以组的形式进行调度。使用方式是如果需要 Coscheduling 功能的 Pod 走新的调度器,其他的例如在线服务的 Pod 走 Kube-scheduler 进行调度。 这些方案虽然能够解决 Coscheduling 的问题,但是同样引入了新的问题。如大家所知,对于同一集群资源,调度器需要中心化。但如果同时存在两个调度器的话,有可能会出现决策冲突,例如分别将同一块资源分配给两个不同的 Pod,导致某个 Pod 调度到节点后因为资源不足,导致无法创建的问题。解决的方式只能是通过标签的形式将节点强行的划分开来,或者部署多个集群。这种方式通过同一个 Kubernetes 集群来同时运行在线服务和离线作业,势必会导致整体集群资源的浪费以及运维成本的增加。再者,Volcano 运行需要启动定制的 MutatingAdmissionWebhook 和 ValidatingAdmissionWebhook。这些 Webhooks 本身存在单点风险,一旦出现故障,将影响集群内所有 pod 的创建。另外,多运行一套调度器,本身也会带来维护上的复杂性,以及与上游 Kube-scheduler 接口兼容上的不确定性。 《进击的 Kubernetes 调度系统 (一):Scheduling Framework?》介绍了 Kubernetes Scheduling Framework 的架构原理和开发方法。在此基础上,我们扩展实现了 Coscheduling 调度插件,帮助 Kubernetes 原生调度器支持批作业调度,同时避免上述方案存在的问题。Scheduling framework 的内容在前一篇文章详细介绍,欢迎大家翻阅。 Kubernetes 负责 Kube-scheduler 的小组 sig-scheduler 为了更好的管理调度相关的 Plugin,新建了项目 scheduler-plugins 管理不同场景的 Plugin。我们基于 scheduling framework 实现的 Coscheduling Plugin 成为该项目的第一个官方插件,下面我将详细的介绍 Coscheduling Plugin 的实现和使用方式。 我们通过 label 的形式来定义 PodGroup 的概念,拥有同样 label 的 Pod 同属于一个 PodGroup。min-available 是用来标识该 PodGroup 的作业能够正式运行时所需要的最小副本数。 备注: 要求属于同一个 PodGroup 的 Pod 必须保持相同的优先级 Framework 的 Permit 插件提供了延迟绑定的功能,即 Pod 进入到 Permit 阶段时,用户可以自定义条件来允许 Pod 通过、拒绝 Pod 通过以及让 Pod 等待状态 (可设置超时时间)。Permit 的延迟绑定的功能,刚好可以让属于同一个 PodGruop 的 Pod 调度到这个节点时,进行等待,等待积累的 Pod 数目满足足够的数目时,再统一运行同一个 PodGruop 的所有 Pod 进行绑定并创建。 举个实际的例子,当 JobA 调度时,需要 4 个 Pod 同时启动,才能正常运行。但此时集群仅能满足 3 个 Pod 创建,此时与 Default Scheduler 不同的是,并不是直接将 3 个 Pod 调度并创建。而是通过 Framework 的 Permit 机制进行等待。 此时当集群中有空闲资源被释放后,JobA 的中 Pod 所需要的资源均可以满足。 则 JobA 的 4 个 Pod 被一起调度创建出来,正常运行任务。 由于 Default Scheduler 的队列并不能感知 PodGroup 的信息,所以 Pod 在出队时处于无序性 (针对 PodGroup 而言)。如下图所示,a 和 b 表示两个不同的 PodGroup,两个 PodGroup 的 Pod 在进入队列时,由于创建的时间交错导致在队列中以交错的顺序排列。 当一个新的 Pod 创建后,入队后,无法跟与其相同的 PodGroup 的 Pod 排列在一起,只能继续以混乱的形式交错排列。 这种无序性就会导致如果 PodGroupA 在 Permit 阶段处于等待状态,此时 PodGroupB 的 Pod 调度完成后也处于等待状态,相互占有资源使得 PodGroupA 和 PodGroupB 均无法正常调度。这种情况即是把死锁现象出现的位置从 Node 节点移动到 Permit 阶段,无法解决前文提到的问题。 针对如上所示的问题,我们通过实现 QueueSort 插件, 保证在队列中属于同一个 PodGroup 的 Pod 能够排列在一起。我们通过定义 QueueSort 所用的 Less 方法,作用于 Pod 在入队后排队的顺序: 首先,继承了默认的基于优先级的比较方式,高优先级的 Pod 会排在低优先级的 Pod 之前。 然后,如果两个 Pod 的优先级相同,我们定义了新的排队逻辑来支持 PodGroup 的排序。 通过如上的排队策略,我们实现属于同一个 PodGroup 的 Pod 能够同一个 PodGroup 的 Pod 能够排列在一起。 当一个新的 Pod 创建后,入队后,会跟与其相同的 PodGroup 的 Pod 排列在一起。 为了减少无效的调度操作,提升调度的性能,我们在 Prefilter 阶段增加一个过滤条件,当一个 Pod 调度时,会计算该 Pod 所属 PodGroup 的 Pod 的 Sum(包括 Running 状态的),如果 Sum 小于 min-available 时,则肯定无法满足 min-available 的要求,则直接在 Prefilter 阶段拒绝掉,不再进入调度的主流程。 如果某个 Pod 在 Permit 阶段等待超时了,则会进入到 UnReserve 阶段,我们会直接拒绝掉所有跟 Pod 属于同一个 PodGroup 的 Pod,避免剩余的 Pod 进行长时间的无效等待。 用户既可以在自己搭建的 Kubernetes 集群中,也可以在任一个公有云提供的标准 Kubernetes 服务中来试用 Coscheduling。需要注意的是集群版本 1.16+, 以及拥有更新集群 master 的权限。 本文将使用 阿里云容器服务 ACK 提供的 Kubernetes 集群来进行测试。 我们已经将 Coscheduling 插件和原生调度器代码统一构建成新的容器镜像。并提供了一个 helm chart 包 ack-coscheduling 来自动安装。它会启动一个任务,自动用 Coscheduling scheduler 替换集群默认安装的原生 scheduler,并且会修改 scheduler 的相关 Config 文件,使 scheduling framework 正确地加载 Coscheduling 插件。完成试用后,用户可通过下文提示的卸载功能恢复集群默认 scheduler 及相关配置。 下载 helm chart 包,执行命令安装: 在 Master 节点上,使用 helm 命令验证是否安装成功。 通过 helm 卸载,将 kube-scheduler 的版本及配置回滚到集群默认的状态。 使用 Coscheduling 时,只需要在创建任务的 yaml 描述中配置 pod-group.scheduling.sigs.k8s.io/name 和 pod-group.scheduling.sigs.k8s.io/min-available 这两个 label 即可。 备注: 属于同一个 PodGroup 的 Pod 必须保持相同的优先级。 接下来我们通过运行 Tensorflow 的分布式训练作业来演示 Coscheduling 的效果。当前测试集群有 4 个 GPU 卡 Arena 是基于 Kubernetes 的机器学习系统开源社区 Kubeflow 中的子项目之一。Arena 用命令行和 SDK 的形式支持了机器学习任务的主要生命周期管理(包括环境安装,数据准备,到模型开发,模型训练,模型预测等),有效提升了数据科学家工作效率。 检查是否部署成功: 删除上述 TFJob yaml 中的 pod-group.scheduling.sigs.k8s.io/name 和 pod-group.scheduling.sigs.k8s.io/min-available 标签,表示该任务不使用 Coscheduling。创建任务后,集群资源只能满足 2 个 Worker 启动,剩余两个处于 Pending 状态。 查看其中正在运行的 Worker 的日志,都处于等待剩余那两个 Worker 启动的状态。此时,4 个 GPU 都被占用却没有实际执行任务。 添加 pod-group 相关标签后创建任务,因为集群的资源无法满足用户设定的 min-available 要求,则 PodGroup 无法正常调度,所有的 Pod 一直处于 Pending 状态。 此时,如果通过集群扩容,新增 4 个 GPU 卡,资源能满足用户设定的 min-available 要求,则 PodGroup 正常调度,4 个 Worker 开始运行。 查看其中一个 Worker 的日志,显示训练任务已经开始: 利用 Kubernetes Scheduling Framework 的机制实现了 Coscheduling,解决了 AI、数据计算类的批任务需要组合调度,同时减少资源浪费的问题。从而提升集群整体资源利用率。 作者介绍: 张凯,阿里云高级技术专家,从事容器服务?ACK?和云原生 AI 解决方案的研发和客户支持,以及相关领域的开源建设。拥有 10 余年大规模深度学习平台,云计算,SOA 等领域经验。 “阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的公众号。” 进击的 Kubernetes 调度系统(二):支持批任务的 Coscheduling/Gang sc 标签:png 官方 lte 机器 内容 自增 运行时 执行 VID 原文地址:https://blog.51cto.com/13778063/2510813
前言
为什么 Kubernetes 调度系统需要 Coscheduling?
社区相关的方案
基于 Scheduling Framework 的方案
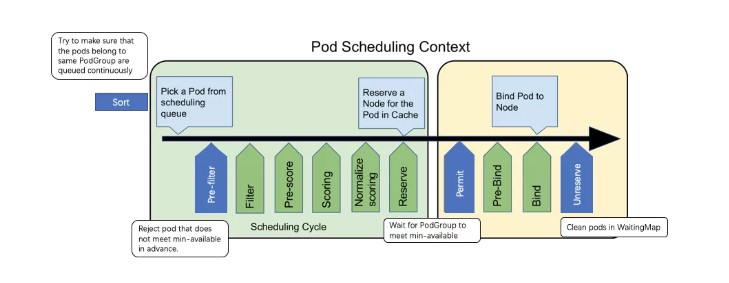
技术方案
总体架构
PodGroup
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "2"Permit
QueueSort


func Less(podA *PodInfo, podB *PodInfo) bool
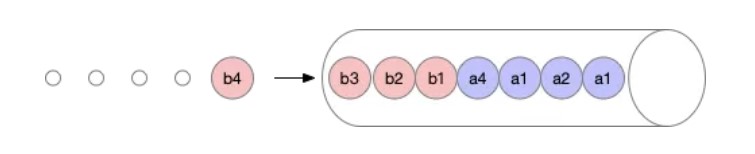
Prefilter
UnReserve
Coscheduling 试用
安装部署
前提条件
部署 Coscheduling
$ wget http://kubeflow.oss-cn-beijing.aliyuncs.com/ack-coscheduling.tar.gz
$ tar zxvf ack-coscheduling.tar.gz
$ helm install ack-coscheduling -n kube-system ./ack-coscheduling
NAME: ack-coscheduling
LAST DEPLOYED: Mon Apr 13 16:03:57 2020
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: None验证 Coscheduling
$ helm get manifest ack-coscheduling -n kube-system | kubectl get -n kube-system -f -
NAME COMPLETIONS DURATION AGE
scheduler-update-clusterrole 1/1 8s 35s
scheduler-update 3/1 of 3 8s 35s卸载 Coscheduling
$ helm uninstall ack-coscheduling -n kube-system使用方式
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "3"
Demo 展示
git clone https://github.com/kubeflow/arena.git
kubectl create ns arena-system
kubectl create -f arena/kubernetes-artifacts/jobmon/jobmon-role.yaml
kubectl create -f arena/kubernetes-artifacts/tf-operator/tf-crd.yaml
kubectl create -f arena/kubernetes-artifacts/tf-operator/tf-operator.yaml$ kubectl get pods -n arena-system
NAME READY STATUS RESTARTS AGE
tf-job-dashboard-56cf48874f-gwlhv 1/1 Running 0 54s
tf-job-operator-66494d88fd-snm9m 1/1 Running 0 54s
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "tf-smoke-gpu"
spec:
tfReplicaSpecs:
PS:
replicas: 1
template:
metadata:
creationTimestamp: null
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "5"
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=cpu
- --data_format=NHWC
image: registry.cn-hangzhou.aliyuncs.com/kubeflow-images-public/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
cpu: ‘1‘
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
Worker:
replicas: 4
template:
metadata:
creationTimestamp: null
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "5"
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=gpu
- --data_format=NHWC
image: registry.cn-hangzhou.aliyuncs.com/kubeflow-images-public/tf-benchmarks-gpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
nvidia.com/gpu: 2
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
tf-smoke-gpu-ps-0 1/1 Running 0 6m43s
tf-smoke-gpu-worker-0 1/1 Running 0 6m43s
tf-smoke-gpu-worker-1 1/1 Running 0 6m43s
tf-smoke-gpu-worker-2 0/1 Pending 0 6m43s
tf-smoke-gpu-worker-3 0/1 Pending 0 6m43s$ kubectl logs -f tf-smoke-gpu-worker-0
INFO|2020-05-19T07:02:18|/opt/launcher.py|27| 2020-05-19 07:02:18.199696: I tensorflow/core/distributed_runtime/master.cc:221] CreateSession still waiting for response from worker: /job:worker/replica:0/task:3
INFO|2020-05-19T07:02:28|/opt/launcher.py|27| 2020-05-19 07:02:28.199798: I tensorflow/core/distributed_runtime/master.cc:221] CreateSession still waiting for response from worker: /job:worker/replica:0/task:2
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
tf-smoke-gpu-ps-0 0/1 Pending 0 43s
tf-smoke-gpu-worker-0 0/1 Pending 0 43s
tf-smoke-gpu-worker-1 0/1 Pending 0 43s
tf-smoke-gpu-worker-2 0/1 Pending 0 43s
tf-smoke-gpu-worker-3 0/1 Pending 0 43s$ kubectl get pods
NAME READY STATUS RESTARTS AGE
tf-smoke-gpu-ps-0 1/1 Running 0 3m16s
tf-smoke-gpu-worker-0 1/1 Running 0 3m16s
tf-smoke-gpu-worker-1 1/1 Running 0 3m16s
tf-smoke-gpu-worker-2 1/1 Running 0 3m16s
tf-smoke-gpu-worker-3 1/1 Running 0 3m16s$ kubectl logs -f tf-smoke-gpu-worker-0
INFO|2020-05-19T07:15:24|/opt/launcher.py|27| Running warm up
INFO|2020-05-19T07:21:04|/opt/launcher.py|27| Done warm up
INFO|2020-05-19T07:21:04|/opt/launcher.py|27| Step Img/sec loss
INFO|2020-05-19T07:21:05|/opt/launcher.py|27| 1 images/sec: 31.6 +/- 0.0 (jitter = 0.0) 8.318
INFO|2020-05-19T07:21:15|/opt/launcher.py|27| 10 images/sec: 31.1 +/- 0.4 (jitter = 0.7) 8.343
INFO|2020-05-19T07:21:25|/opt/launcher.py|27| 20 images/sec: 31.5 +/- 0.3 (jitter = 0.7) 8.142后续工作
王庆璨,阿里云技术专家,专注于大规模集群资源管理和调度。Kubernetes 社区成员,主要参与 Kube-scheduler 社区开发。目前负责阿里云容器服务 ACK?资源调度和云原生 AI 相关工作。
文章标题:进击的 Kubernetes 调度系统(二):支持批任务的 Coscheduling/Gang sc
文章链接:http://soscw.com/index.php/essay/44588.html