KMP 算法的两种实现
2021-01-25 01:15
标签:子字符串查找 amp 交集 基本 改进 problems 每日一题 str get KMP 算法在 LeetCode 刷题的过程中看见过好几次,这几天终于去学习了一下,然后,我就发现,Google 出来的 KMP 和我书上的不太一样…… 我的书是《算法 第 4 版》,上面的 KMP 是基于 DFA 实现的,而 Google 出来的大多是基于 PMT 的,似乎是《算法导论》那本书上的。 虽然实现方式咋一看是不一样的,但是了解了一番后,发现,两个实现思路是一样的,难怪都叫 KMP 算法。 这篇博客的主要内容就是 KMP 算法的这两种实现和它们间的一些联系。 KMP 算法是用来解决 子字符串查找 问题的算法,这个问题有一个很朴素(暴力)的解决方式,通常的写法是: 在查找过程中,分别使用了文本指针 虽然朴素算法在大多数情况下能够工作的很好,但是在遇到类似 而 KMP 算法能够以最坏为 \(O(M + N)\) 级别的时间复杂度解决这个问题。 无论是基于 DFA 的 KMP 实现还是基于 PMT 的 KMP 实现,两者的基本思想都是一样的,就是在出现不匹配时,利用已知的一部分文本的内容避免回退文本指针, 而是只回退模式指针。 比如说在模式指针在 也就是说,接下来要尝试匹配的文本字符串是以 这样一来,所有已经匹配过的文本字符都不需要重新匹配,只需要不断调整模式字符串完成匹配就可以了。 DFA 也就是确定有限自动状态机,第一次接触这个概念还是在编译原理里面。在基于 DFA 的 KMP 中,我们首先需要根据模式字符串构建一个这样的状态机: 比如,基于模式字符串 解释: 可以通过 在朴素算法中,在位置 我们把这个状态叫做【重启状态】,在状态 假设状态 同时,状态 我们可以轻易得到状态为 使用 DFA 来查找子字符串的过程就很简单了,就是跑这个状态机的过程: 完整的实现: 相对来说,基于 PMT 的 KMP 实现理解起来更加简单,其中,PMT 是一个被称为部分匹配表(Partial Match Table)的数组: 对于字符串 ABA 来说,它的前缀集合为 [A, AB],后缀集合为 [BA, A],两者的交集为 [A],最长元素的长度为 1。 通过这个 PMT 数组,我们可以加速子字符串的查找过程: 当我们在模式指针 这时,我们可以尽可能地尝试匹配串 如上图(来自 - 如何更好地理解和掌握 KMP 算法? - 海纳的回答 - 知乎)。 PS: 这里需要注意长度值和数组索引值之间的差异,有点绕 可以看到,我们可以通过 PMT 数组来完成查找过程,但是每次匹配失败后都需要取 如下图(来自 - 如何更好地理解和掌握 KMP 算法? - 海纳的回答 - 知乎): 这样,我们在匹配失败时就可以根据 next 调整模式指针,具体查找逻辑就为: next[0] = -1, 当 txt[i] != pat[0] 时,j 的值会变为 -1,这时就可以进入另一个分支让 i + 1 并让 j 归 0 现在的问题是,如何构建这个 假如该值等于 2,那么就是说存在类似 如果,这个时候,满足 可以发现: 如果不满足,那么,也就是说,最大公共长度还位于 更短 的串中,也就是在 此时,便可以重复前面的过程,判断 构造 完整实现: KMP 算法的历史故事: 在 1970 年,S.Cook 在理论上证明了一个关于某种特定类型的抽象计算机的结论。这个结论暗示了一种在最坏情况下用时也只是与 M + N 成正比的解决子字符串查找问题的算法。 D.E.Knuth 和 V.R.Pratt 改进了 Cook 用来证明定理的框架并将它提炼为一个相对简单而实用的算法。 J.H.Morris 在实现一个文本编辑器时,未来解决某个棘手的问题也发明了几乎相同的算法。 虽然不知道是谁搞得 DFA,又是谁搞得 PMT,但是,两个的实现思路其实是很接近的。在讨论构建 DFA 的过程中,有一个【重启状态】, 表示的是在位置 比如 通过思考尝试可以发现,在构造 DFA 的过程中,重启状态 X 的序列就是 PMT 数组!!! 真的好巧 ( ?? ω ?? )? 决定要看一下 KMP 是因为前几天 LeetCode 上的每日一题 另一个树的子树,难度是简单,我用 DFS 暴力 AC 后去看了一下题解…… 评论区的一个评论是这样的:竟然用一个题涵盖 KMP DFS HASH 埃氏筛选法 收藏从未停止 学习从未开始。 而我的心情是这样的:( ̄︶ ̄)↗ => (⊙_⊙)? 讲道理,这样的题基本没见过几个,恰好又用了 Copy 过几次的 KMP,所以就来研究了一下。 感觉还可以 (~ ̄▽ ̄)~ 1 这里的 -1 和 next 数组都是为了编程方便,也可以选择不这样做 KMP 算法的两种实现 标签:子字符串查找 amp 交集 基本 改进 problems 每日一题 str get 原文地址:https://www.cnblogs.com/rgbit/p/12863617.html
前言
朴素子字符串查找算法
def bf_search(txt: str, pat: str) -> int:
txt_len, pat_len = len(txt), len(pat)
for i in range(txt_len - pat_len + 1):
for j in range(pat_len):
if not txt[i + j] == pat[j]:
break
if j == pat_len:
return i
return -1
i 和模式指针 j 来进行匹配操作,发现不匹配时,会隐式回退两个指针, 下面是显式回退的版本:def bf_search(txt: str, pat: str) -> int:
i, j, txt_len, pat_len = 0, 0, len(txt), len(pat)
while i AAAAAAAAAAB 和 AAAB 的情况时, 对于每一个文本指针 i 都会遍历一次模式字符串,时间复杂度达到 \(O(MN)\) 的级别。KMP 算法的基本思想
j 处出现了不匹配的情况,那么,这个时候,文本字符串必然已经匹配了 pat[0:j] 这部分模式字符串,此时,在朴素算法中, 我们会回退文本指针并在 右移一位 后继续尝试匹配模式字符串。pat[1:j] 这个前缀开头的字符串,我们可以利用这一特性,避免重新匹配这个前缀。基于 DFA 的 KMP 实现
[0, len(pat)], 状态为 len(pat) 时,说明成功完成模式字符串的匹配ABABAC 构建得到的状态机是这样的: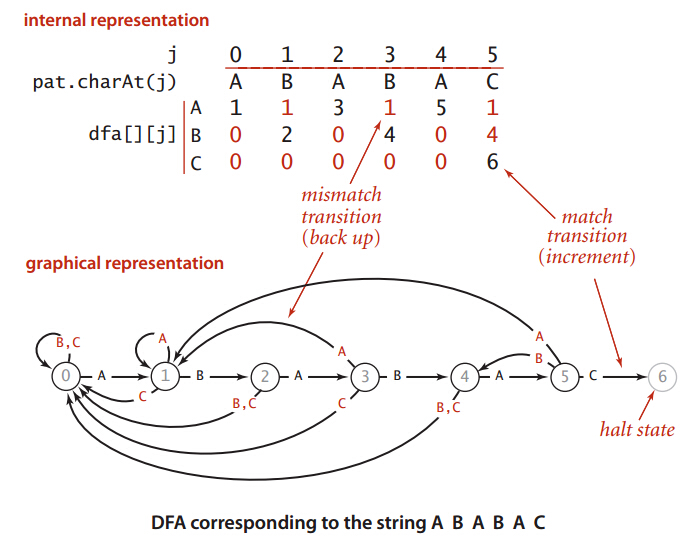
0 且输入的字符是 A 时,说明匹配字符 pat[0] 成功,下一个需要匹配的字符为 pat[1], 因此下一个状态为 1
0 且输入的字符不是 A 时,说明匹配字符 pat[0] 失败,需要移动文本字符并重新从状态 0 开始匹配,因此下一个状态为 0
[输入][状态] = 下一个状态 或 [状态][输入] = 下一个状态 的形式来表示这个状态机,当状态对应的 模式字符 和输入对应的 文本字符 相同时, 说明匹配成功,下一个状态必然为 当前状态 + 1, 也就是说,我们需要考虑的是不同时应该怎么解决。j 出现不匹配时,我们会回退文本指针并右移 1 位重新开始匹配,这时,这部分 文本字符串 字串等于 pat[1:j] 这个 模式字符串 子串:txt: A B A B A D A
i
pat: A B A B A C
1 j
5
pat[1:j] 对应的是 BABA 这个子串,把这个子串放到 DFA 中重新匹配最后可以达到的状态为 3,也就是说,在匹配过程中,就算匹配失败,重新匹配时, 也必然会在继续匹配到 j - 1 时到达另一个状态。j 处匹配成功时,下一个状态为 j + 1,匹配失败时,重新匹配会在状态 j - 1 处到达重启状态,此时, 在状态 j 处的状态转换应该和 重启状态 处的状态转换相同。j 的重启状态为 X,那么状态 j 处可能的转换就应该是:for ch in pat_chrs: # 遍历模式字符串中的字符
dfa[ch][j] = dfa[ch][x] # 不匹配时转换和重启状态 x 处相同
dfa[pat[j]][j] = j + 1 # 匹配时下一个状态为 j + 1
j 和状态 j + 1 的重启状态是存在递推关系的,假如状态 j 的重启状态为 X,那么,我们将我们将 j 处的字符作为重启状态的输入, 得到的下一个值不就应该是 j + 1 的重启状态了吗?x = dfa[pat[j]][x] # state x, in pat[j]
0 时的状态转换和重启状态(你第一个字符都不匹配,重启状态肯定是 0 啊),然后根据状态的转换规律就可以很容易的构建 DFA 了:x, dfa[pat[0]][0] = 0, 1
for j in range(1, pat_len):
for ch in pat_chrs:
dfa[ch][j] = dfa[ch][x]
dfa[pat[j]][j] = j + 1
x = dfa[pat[j]][x] # j + 1 时的重启状态
while i j, in => txt[i], next state => dfa[txt[i]][j]
i += 1
if j == pat_len:
return i - pat_len
return -1
def kmp_search(txt: str, pat: str) -> int:
txt_len, pat_len = len(txt), len(pat)
def make_dfa():
dfa = [{} for i in range(pat_len)] # [state][in] => next state
x, dfa[0][pat[0]] = 0, 1
for j in range(1, pat_len):
for ch in pat:
dfa[j][ch] = dfa[x].get(ch, 0)
dfa[j][pat[j]] = j + 1
x = dfa[x].get(pat[j], 0)
return dfa
i, j, dfa = 0, 0, make_dfa()
while i 基于 PMT 的 KMP 实现
PMT[i] 的值为 v 时,表示子串 pat[0: i + 1] 前缀集合与后缀集合的交集中最长元素的长度为 v
j 处匹配失败时,我们可以知道的是,前一段文本字符串为 pat[0:j],需要重新匹配的部分为 pat[1:j]pat[1:j] 的后缀和 pat 的前缀,在匹配成功部分的后面继续匹配模式字符串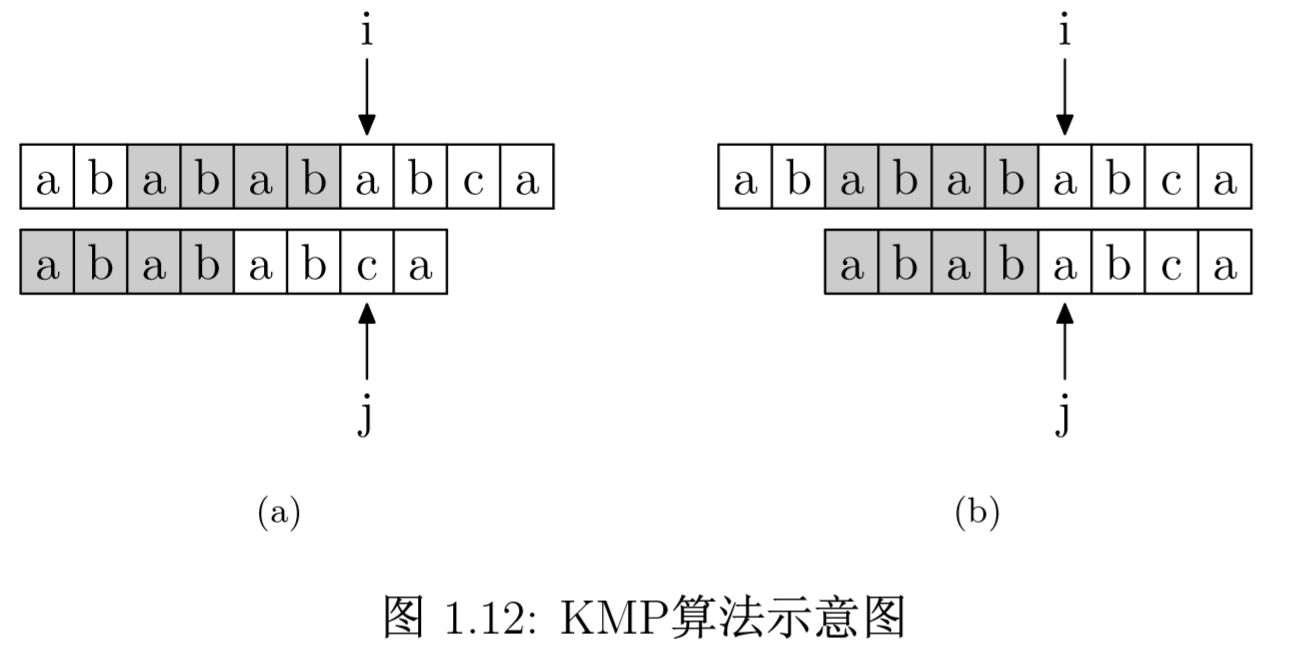
PMT[j - 1] 中的值保存了子串 pat[0:j] 前缀集合与后缀集合的交集中最长元素的长度 v,因此,我们可以直接使用这个值, 将模式指针的值更新为 vj - 1 处的值太麻烦,因此,可以将 PMT 数组整体右移 1 位, 将索引为 0 处的值设为 -1,就得到了新的 next 数组1。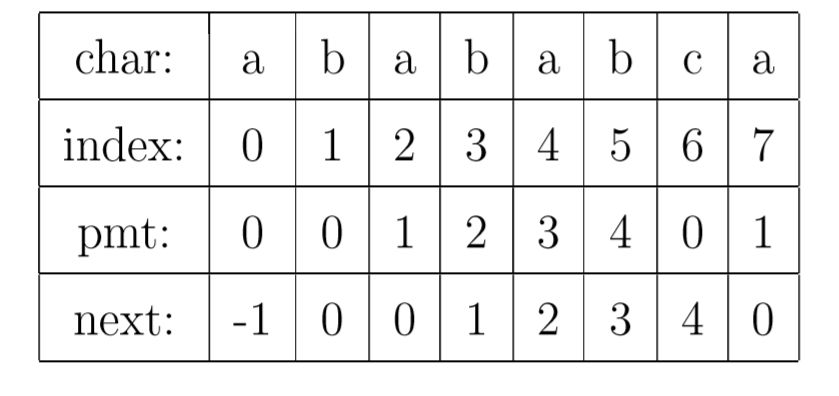
def kmp_search(txt: str, pat: str) -> int:
txt_len, pat_len = len(txt), len(pat)
i = j = 0
while i
next 数组,很巧的是,这个构建过程也是有规律的,由于值 PMT[j] 表示的是串 pat[0:j + 1] 中的最大公共长度, 那么,值 next[j] 表示的是串 pat[0:j] 中的最大公共长度。AB...AB 的情况:0 j
A B ... A B ?
pat[next[j]] = pat[j] 这个条件,比如说是字符 C,那么,就变成了 ABC...ABC 这个情况,即:0 j
A B C ... A B C
2
|
pat[next[j]]
pat[next[j]] = pat[j] 时,值 next[j + 1] 也就等于 next[next[j]] + 1
pat[0:next[j]] 的内部:0 j
A B D ... A B A
--- 2
|
pat[0:next[j]]
pat[next[next[j]]] = pat[j] 是否成立,这里恰好一样,值 next[next[j]] 为 0,因此 next[j + 1] 的值就为 0 + 1。next 数组时便可以重复上述过程,直到 next[j] = pat[j] 或 j = 0 为止:def make_next(pat):
i, j, pat_len, next = 0, -1, len(pat), [-1]
while i def kmp_search(txt: str, pat: str) -> str:
txt_len, pat_len = len(txt), len(pat)
def make_next():
i, j, next = 0, -1, [-1]
while i 历史渊源 & DFA & PMT
j 处匹配失败后,重新匹配可以达到的状态。ABABA 最后的重启状态到达的位置为 ABA, 这个串是啥?不就是串 ABABA 的最大公共长度吗?结语
参考链接
Footnotes
下一篇:【Python】os库的使用