php内部解析,附带1.8可能出现的问题的不定时
2021-02-08 01:18
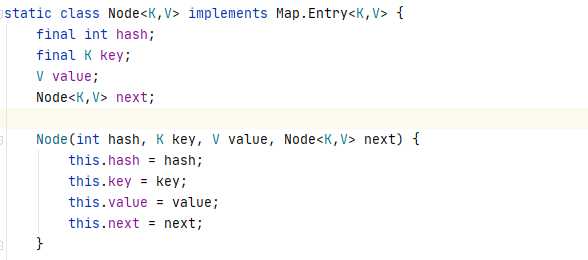
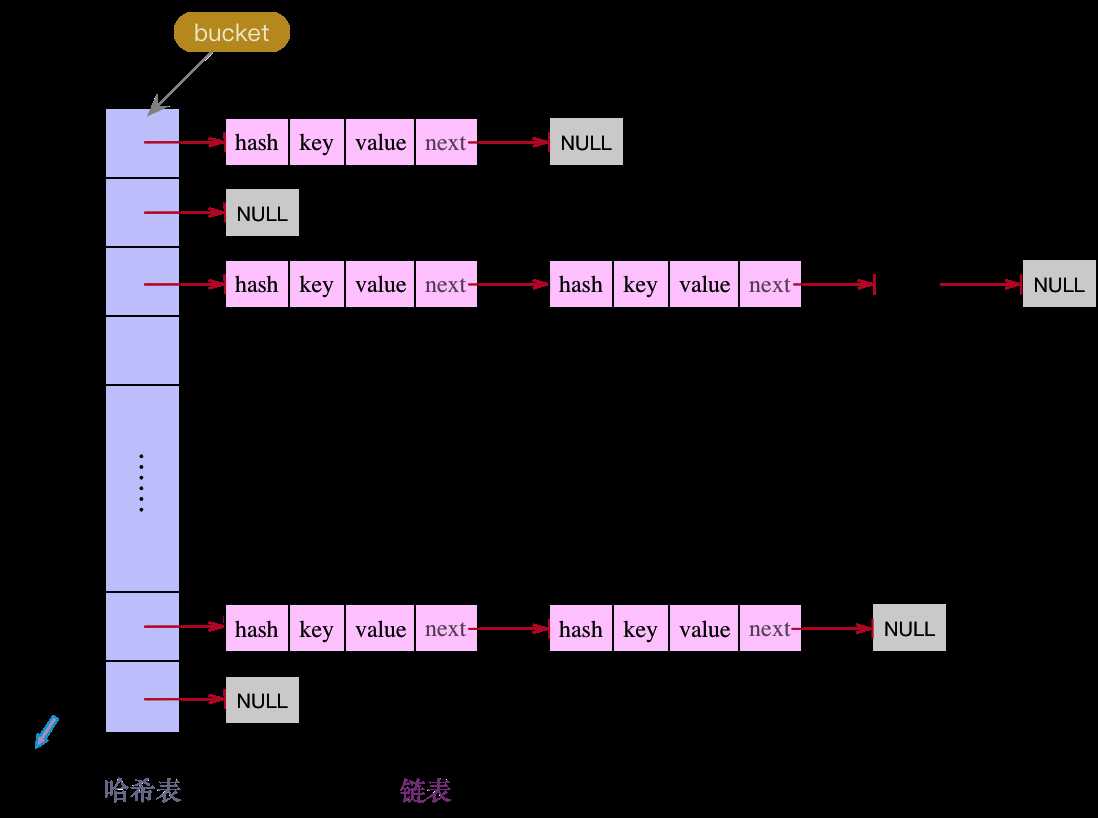
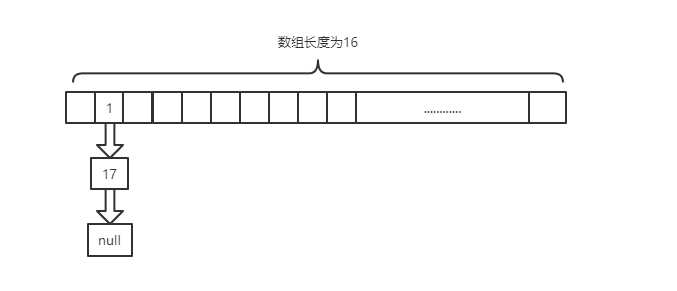
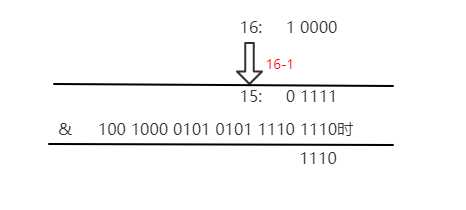
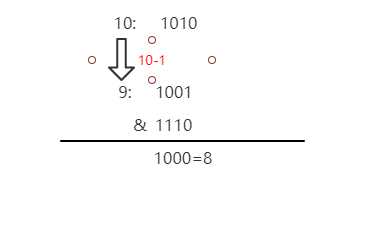
标签:建立 用户 bsp java except frequency 要求 相等 ++ 按问题的形式来吧,这些大多是我自己总结的,如有错误请及时指正谢谢 首先,HashMap是一种数据结构,可以快速的帮我们存取数据。它的底层数据结构在1.7和1.8有了一些变化,1.7版本及以前他是数组+链表的形式,1.8及以后数组+链表+红黑树,如果链表长度大于等于8就会转化为红黑树,如果长度降至6红黑树会转化为链表。红黑树的出现解决了因为链表过长导致查询速度变慢的问题,因为链表的查询时间复杂度是O(n),而红黑树的查询时间复杂度是O(logn)。 这个代码是1.8的(1.7是Entry,就是名字不一样),其实我们每一个放进去的(key,value)到最后都会封装成这样的Node对象。Hashmap的数组就是以一系列这样的Node对象构成的数组,链表就是把next指向下一个Node对象。 首先我们要知道什么是Hash算法。 这里放出一段官方的话: Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。 简单点来说:就是把一个大数字经过运算变为固定范围的输出,最简单的算法就是对你的数组长度取模。 但是这样就会出现一个问题,你这么算难免会出现算出来的数字是一样的: 比如数组长度为16,我们要放入数字1和17,那么他们经过对数组长度取模后位置是一样的,这样就产生了Hash冲突。我们就可以在数组下拉出一个链表去存储这个数字 1、开放定址法(就是往下找空余地方) 2、 再哈希法(再进行hash直到无冲突) 3、拉链法(hashmap用的) 链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个结点用单向链表连接起来 4、建立公共溢出区: HashMap中有这样一段注释(主要看数字): TreeNodes占用空间是普通Nodes的两倍(相较于链表结构,链表只有指向下一个节点的指针,二叉树则需要左右指针,分别指向左节点和右节点),所以只有当链表包含足够多的节点时才会转成TreeNodes(考虑到时间和空间的权衡),而是否足够多就是由TREEIFY_THRESHOLD的值决定的。当红黑树中节点数变少时,又会转成普通的链表。并且我们查看源码的时候发现,链表长度达到8就转成红黑树,当长度降到6就转成普通链表。 这样就解释了为什么不是一开始就将其转换为TreeNodes,而是需要一定节点数才转为TreeNodes,说白了就是trade-off,空间和时间的权衡。 当hashCode离散性很好的时候,树型链表用到的概率非常小,因为数据均匀分布在每个链表中,几乎不会有链表中链表长度会达到阈值。但是在随机hashCode下,离散性可能会变差,然而JDK又不能阻止用户实现这种不好的hash算法,因此就可能导致不均匀的数据分布。不过理想情况下随机hashCode算法下所有链表中节点的分布频率会遵循泊松分布,我们可以看到,一个链表中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件。这种不可能事件都发生了,说明链表中的节点数很多,查找起来效率不高。至于7,是为了作为缓冲,可以有效防止链表和树频繁转换。 之所以选择8,不是拍拍屁股决定的,而是根据概率统计决定的。由此可见,发展30年的Java每一项改动和优化都是非常严谨和科学的。 个人总结: HashMap的初始容量16,加载因子为0.75,扩容增量是原容量的1倍。如果HashMap的容量为16,一次扩容后容量为32。HashMap扩容是指元素个数(包括数组和链表+红黑树中)超过了16*0.75=12(容量×加载因子)之后开始扩容。 这个就是源码里的声明 加载因子越大,填满的元素越多,空间利用率越高,但冲突的机会加大了。 所以这是一个时间和空间的均衡。 这个问题我以前见到过,所以拿出来说一下。 首先HashMap的构造方法有四个 简单点来说就是你可以自定义加载因子和初始容量。但是这个初始容量不是说你设置多少就是多少,他是会有个计算的,到最后Hashmap的容量一定是2的n次方 简单说一下putMapEntries 所以说这个答案就是不会扩容的,因为你初始它的容量是100,tableSizeFor也会自动变成128,128×0.75是93远远大于75. 主要是为了计算hash值时散列性更好。 我们看一下HashMap的数组下标如何计算的 假定HashMap的长度为默认的16,则n - 1为15,也就是二进制的01111 可以说,Hash算法最终得到的index结果完全取决于hashCode的最后几位。 那么说为什么别的数字不行呢? 假设,HashMap的长度为10,则n-1为9,也就是二进制的1001 我们来试一个hashCode:1110时,通过Hash算法得到的最终的index是8 再比如说:1000得到的index也是8。 也就是说,即使我们把倒数第二、三位的0、1变换,得到的index仍旧是8,说明有些index结果出现的几率变大! 这样,显然不符合Hash算法均匀分布的要求。 反观,长度16或其他2的幂次方,Length - 1的值的二进制所有的位均为1,这种情况下,Index的结果等于hashCode的最后几位。只要输入的hashCode本身符合均匀分布,Hash算法的结果就是均匀的。 一句话,HashMap的长度为2的幂次方的原因是为了减少Hash碰撞,尽量使Hash算法的结果均匀分布。 在讲解put方法之前,先看看hash方法,看怎么计算哈希值的。 put方法实际调用了putVal方法 大概如下几步: ①. 判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容,初始容量是16; ②. 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③; ③. 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals; ④. 判断table[i] 是否为TreeNode,即table[i] 是否是红黑树,如果是红黑树,遍历发现该key不存在 则直接在树中插入键值对;遍历发现key已经存在直接覆盖value即可; ⑤. 如果table[i] 不是TreeNode则是链表节点,遍历发现该key不存在,则先添加在链表结尾, 判断链表长度是否大于8,大于8的话把链表转换为红黑树;遍历发现key已经存在直接覆盖value即可; ⑥. 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。 何时进行扩容? HashMap使用的是懒加载,构造完HashMap对象后,只要不进行put 方法插入元素之前,HashMap并不会去初始化或者扩容table。 当首次调用put方法时,HashMap会发现table为空然后调用resize方法进行初始化 但是在新的下标位置计算上1.8做了很大的优化,后面会说到。 JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7认为最新插入的应该会先被用到,所以用了头插法,但当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。 说一下为什么会产生死循环问题: 问题出现在了这个移动元素的transfer方法里 主要问题就出在了这行代码上 如果两个线程A,B都要对这个map进行扩容 A和B都已经创建了新的数组,假设线程A在执行到Entry next = e.next之后,cpu时间片用完了,这时变量e指向节点a,变量next指向节点b。 此时A的状态:e=a ,next=b 线程B继续执行,很不巧,a、b、c节点rehash之后又是在同一个位置,开始移动节点, 因为头插法,复制后顺序是反的,结束后B的状态: 此时A开始执行,此时变量e指向节点a,变量next指向节点b,开始执行循环体的剩余逻辑 执行到 此时A的状态 执行到 此时e=b 再执行一波循环,Entry 在JDK1.7的时候是重新计算数组下标 而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。 就比如说:数组大小是4,hash算法是对长度取模 扩容后是这样的 我们可以把这三个数的二进制和扩容后的length-1进行按位与,可以看到只有数字5新增位为1 因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap” 不是线程安全的,多线程下会出现死循环和put操作时可能导致元素丢失 死循环原因:上边已经分析过了 丢失原因:当多个线程同时执行addEntry(hash,key ,value,i)时,如果产生哈希碰撞,导致两个线程得到同样的bucketIndex去存储,就可能会发生元素覆盖丢失的情况 想实现线程安全的解决方法: 1.使用Hashtable 类,Hashtable 是线程安全的(不建议用,就是利用了synchronized进行加锁); 2.使用并发包下的java.util.concurrent.ConcurrentHashMap,ConcurrentHashMap实现了更高级的线程安全; 3.或者使用synchronizedMap() 同步方法包装 HashMap object,得到线程安全的Map,并在此Map上进行操作。 php内部解析,附带1.8可能出现的问题的不定时 标签:建立 用户 bsp java except frequency 要求 相等 ++ 原文地址:https://www.cnblogs.com/thirdkey/p/13085661.html1.你了解HashMap么,可以说说么?
2.它的数组+链表是怎么实现的?
3.为什么要有链表,红黑树?只有数组不可以么?
4.知道哪些常见的解决hash冲突算法么?
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数
计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表5.为什么阈值就是8和6呢?中间的7是有什么作用的呢?直接就是红黑树不可以么?

/*
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when 链表s contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain 链表s. In
* usages with well-distributed user hashCodes, tree 链表s are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in 链表s follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
*/
泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。如果有兴趣的,可以研究一下,概率是怎么算出来的!
6.HashMap的初始容量,加载因子,扩容增量是多少?如果加载因子变大变小会怎么样?
//默认初始容量
static final int DEFAULT_INITIAL_CAPACITY = 1
反之,加载因子越小,填满的元素越少,冲突的机会减小,但空间浪费多了(因为需要经常扩容)。7. 如果我默认初始大小为100,那么元素个数到达75会扩容么?
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor
public HashMap(Map m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
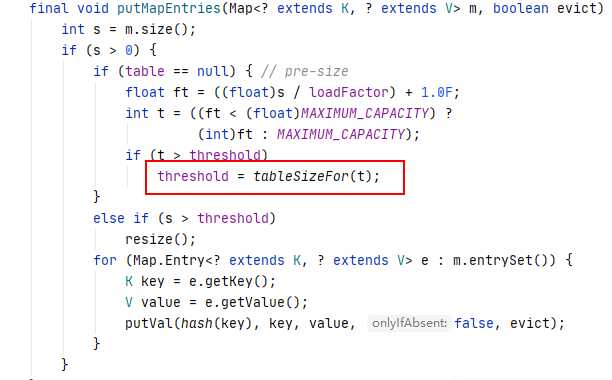
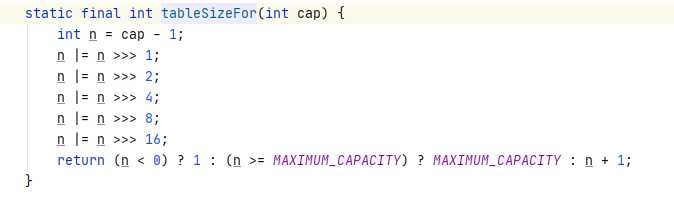
final void putMapEntries(Map extends K, ? extends V> m, boolean evict) {
//获取该map的实际长度
int s = m.size();
if (s > 0) {
//判断table是否初始化,如果没有初始化
if (table == null) { // pre-size
/**求出需要的容量,因为实际使用的长度=容量*0.75得来的,+1是因为小数相除,基本都不会是整数,容量大小不能为小数的,后面转换为int,多余的小数就要被丢掉,所以+1,例如,map实际长度22,22/0.75=29.3,所需要的容量肯定为30,有人会问如果刚刚好除得整数呢,除得整数的话,容量大小多1也没什么影响**/
float ft = ((float)s / loadFactor) + 1.0F;
//判断该容量大小是否超出上限。
int t = ((ft threshold)
threshold = tableSizeFor(t);
}
//如果table已经初始化,则进行扩容操作,resize()就是扩容。
else if (s > threshold)
resize();
//遍历,把map中的数据转到hashMap中。
for (Map.Entry extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
8. HashMap中为什么数组的长度为2的幂次方?
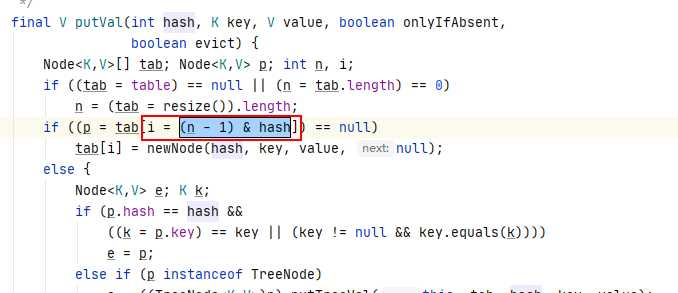
// 将(数组的长度-1)和hash值进行按位与操作:
i = (n - 1) & hash // i为数组对应位置的索引 n为当前数组的大小
9.put方法
static final int hash(Object key) {
int h;
/**先获取到key的hashCode,然后进行移位再进行异或运算,为什么这么复杂,不用想肯定是为了减少hash冲突**/
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
/**四个参数,第一个hash值,第四个参数表示如果该key存在值,如果为null的话,则插入新的value,最后一个参数,在hashMap中没有用,可以不用管,使用默认的即可**/
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//tab 哈希数组,p 该哈希桶的首节点,n hashMap的长度,i 计算出的数组下标
Node
10.resize方法
,当添加完元素后,如果HashMap发现size(元素总数)大于threshold(阈值),则会调用resize方法进行扩容 final Node
11.get方法
public V get(Object key) {
Node
主要就是利用equals和hashcode方法找到并返回
12.HashMap在JDK1.7和1.8除了数据结构的区别
(1)插入数据方式不同:

Entry
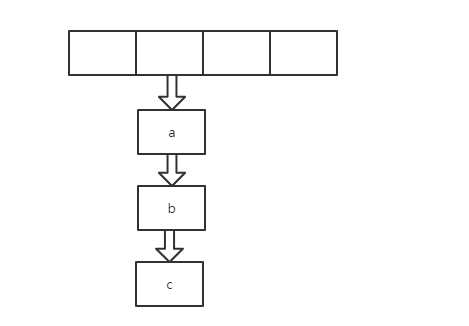
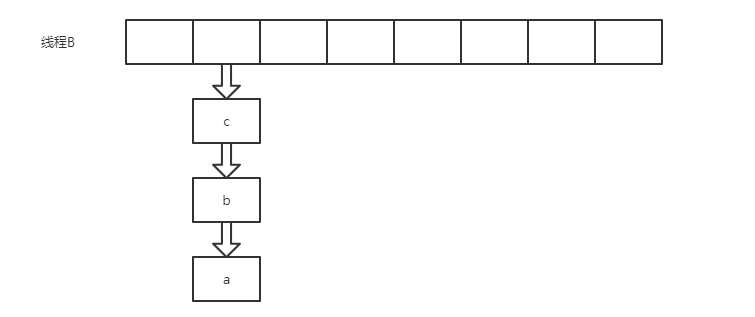
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
newTable[i] = e;
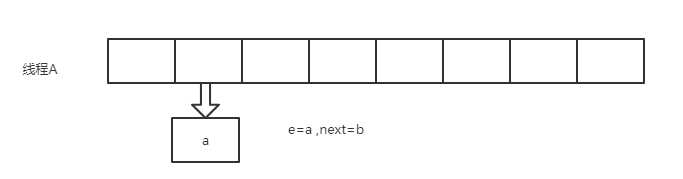
e = next;
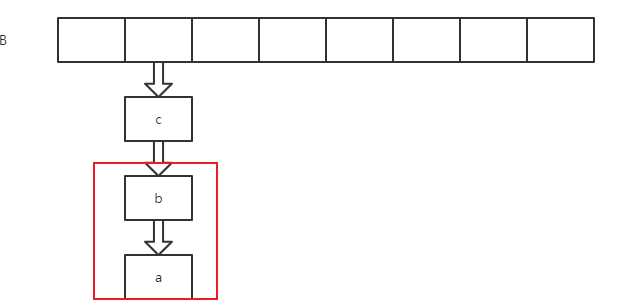
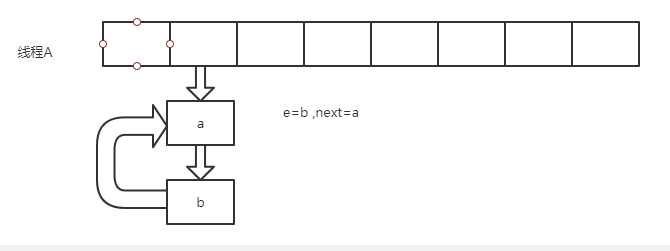
(2)扩容后数据存储位置的计算方式也不一样:
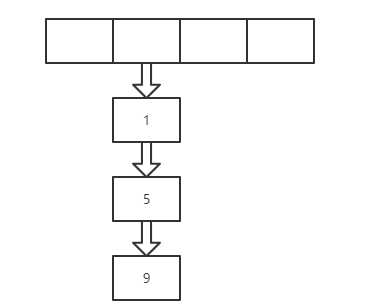
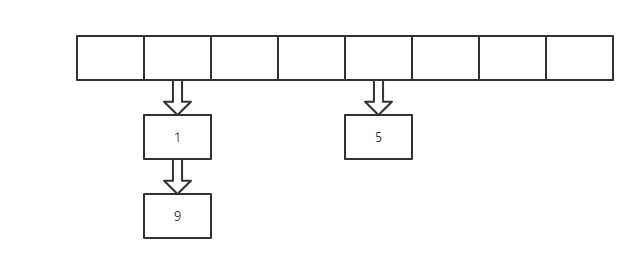

(3)扩容的条件不同,1.7需要容量超过阈值且发生hash冲突,1.8超过阈值即会扩容
(4)JDK1.7的时候是先进行扩容后进行插入,而在JDK1.8的时候则是先插入后进行扩容
(5)1.8中没有区分键为null的情况,而1.7版本中对于键为null的情况调用putForNullKey()方法。但是两个版本中如果键为null,那么调用hash()方法得到的都将是0,所以键为null的元素都始终位于哈希表table【0】中。
(6)jdk1.7中当哈希表为空时,会先调用inflateTable()初始化一个数组;而1.8则是直接调用resize()扩容
(7)jdk1.7中的hash函数对哈希值的计算直接使用key的hashCode值,而1.8中则是采用key的hashCode异或上key的hashCode进行无符号右移16位的结果,避免了只靠低位数据来计算哈希时导致的冲突,计算结果由高低位结合决定,使元素分布更均匀;
13、HashMap是线程安全的么?如果想线程安全怎么办?
文章标题:php内部解析,附带1.8可能出现的问题的不定时
文章链接:http://soscw.com/index.php/essay/52425.html