(一) netty 拆包,粘包处理(自定义协议)
2021-03-05 03:26
标签:copyright 操作 its 有一个 efault trap 监听端口 解决方案 expected 一、netty 为啥要进行拆包粘包处理 简单点描述,netty底层通讯是走的TCP协议,接收到的都是字节流,然后以字节字节队列的形式存在缓存堆里面。而TCP协议每一次最大接收的字节长度是1024个字节,一旦超过这个长度,那么就会出现一下各种形式: 所以在字节长度超过1024的时候,一个完整的包可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。 二、解决方案
* { 通过源码我们可以知道核心方法是: 所以根据自己得协议,写了一个实现方式: 这个写法是基于自定义协议,然后又是非规范协议的操作来实现的。比如类似下面16进制组合ascii码的协议: (一) netty 拆包,粘包处理(自定义协议) 标签:copyright 操作 its 有一个 efault trap 监听端口 解决方案 expected 原文地址:https://www.cnblogs.com/zcsheng/p/12910665.html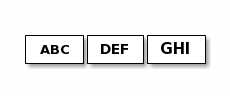
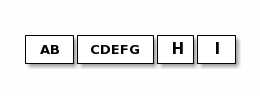
netty基于以上问题也提供了一些组件,比如:
因为是自定义协议,在上面的方式不适用。所以在这里我基于LengthFieldBasedFrameDecoder实现的原理下,重新编写了一个实现方式。
我们先看一下LengthFieldBasedFrameDecoder的代码:
/*
* Copyright 2012 The Netty Project
*
* The Netty Project licenses this file to you under the Apache License,
* version 2.0 (the "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at:
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
* License for the specific language governing permissions and limitations
* under the License.
*/
package io.netty.handler.codec;
import java.nio.ByteOrder;
import java.util.List;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.serialization.ObjectDecoder;
/**
* A decoder that splits the received {@link ByteBuf}s dynamically by the
* value of the length field in the message. It is particularly useful when you
* decode a binary message which has an integer header field that represents the
* length of the message body or the whole message.
*
2 bytes length field at offset 0, do not strip header
*
* The value of the length field in this example is 12 (0x0C) which
* represents the length of "HELLO, WORLD". By default, the decoder assumes
* that the length field represents the number of the bytes that follows the
* length field. Therefore, it can be decoded with the simplistic parameter
* combination.
*
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = 0
* initialBytesToStrip = 0 (= do not strip header)
*
* BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
* +--------+----------------+ +--------+----------------+
* | Length | Actual Content |----->| Length | Actual Content |
* | 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
* +--------+----------------+ +--------+----------------+
*
*
* 2 bytes length field at offset 0, strip header
*
* Because we can get the length of the content by calling
* {@link ByteBuf#readableBytes()}, you might want to strip the length
* field by specifying initialBytesToStrip. In this example, we
* specified 2, that is same with the length of the length field, to
* strip the first two bytes.
*
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = 0
* initialBytesToStrip = 2 (= the length of the Length field)
*
* BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes)
* +--------+----------------+ +----------------+
* | Length | Actual Content |----->| Actual Content |
* | 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
* +--------+----------------+ +----------------+
*
*
* 2 bytes length field at offset 0, do not strip header, the length field
* represents the length of the whole message
*
* In most cases, the length field represents the length of the message body
* only, as shown in the previous examples. However, in some protocols, the
* length field represents the length of the whole message, including the
* message header. In such a case, we specify a non-zero
* lengthAdjustment. Because the length value in this example message
* is always greater than the body length by 2, we specify -2
* as lengthAdjustment for compensation.
*
* lengthFieldOffset = 0
* lengthFieldLength = 2
* lengthAdjustment = -2 (= the length of the Length field)
* initialBytesToStrip = 0
*
* BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
* +--------+----------------+ +--------+----------------+
* | Length | Actual Content |----->| Length | Actual Content |
* | 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
* +--------+----------------+ +--------+----------------+
*
*
* 3 bytes length field at the end of 5 bytes header, do not strip header
*
* The following message is a simple variation of the first example. An extra
* header value is prepended to the message. lengthAdjustment is zero
* again because the decoder always takes the length of the prepended data into
* account during frame length calculation.
*
* lengthFieldOffset = 2 (= the length of Header 1)
* lengthFieldLength = 3
* lengthAdjustment = 0
* initialBytesToStrip = 0
*
* BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
* +----------+----------+----------------+ +----------+----------+----------------+
* | Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
* | 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
* +----------+----------+----------------+ +----------+----------+----------------+
*
*
* 3 bytes length field at the beginning of 5 bytes header, do not strip header
*
* This is an advanced example that shows the case where there is an extra
* header between the length field and the message body. You have to specify a
* positive lengthAdjustment so that the decoder counts the extra
* header into the frame length calculation.
*
* lengthFieldOffset = 0
* lengthFieldLength = 3
* lengthAdjustment = 2 (= the length of Header 1)
* initialBytesToStrip = 0
*
* BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
* +----------+----------+----------------+ +----------+----------+----------------+
* | Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
* | 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
* +----------+----------+----------------+ +----------+----------+----------------+
*
*
* 2 bytes length field at offset 1 in the middle of 4 bytes header,
* strip the first header field and the length field
*
* This is a combination of all the examples above. There are the prepended
* header before the length field and the extra header after the length field.
* The prepended header affects the lengthFieldOffset and the extra
* header affects the lengthAdjustment. We also specified a non-zero
* initialBytesToStrip to strip the length field and the prepended
* header from the frame. If you don‘t want to strip the prepended header, you
* could specify 0 for initialBytesToSkip.
*
* lengthFieldOffset = 1 (= the length of HDR1)
* lengthFieldLength = 2
* lengthAdjustment = 1 (= the length of HDR2)
* initialBytesToStrip = 3 (= the length of HDR1 + LEN)
*
* BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
* +------+--------+------+----------------+ +------+----------------+
* | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
* | 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
* +------+--------+------+----------------+ +------+----------------+
*
*
* 2 bytes length field at offset 1 in the middle of 4 bytes header,
* strip the first header field and the length field, the length field
* represents the length of the whole message
*
* Let‘s give another twist to the previous example. The only difference from
* the previous example is that the length field represents the length of the
* whole message instead of the message body, just like the third example.
* We have to count the length of HDR1 and Length into lengthAdjustment.
* Please note that we don‘t need to take the length of HDR2 into account
* because the length field already includes the whole header length.
*
* lengthFieldOffset = 1
* lengthFieldLength = 2
* lengthAdjustment = -3 (= the length of HDR1 + LEN, negative)
* initialBytesToStrip = 3
*
* BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
* +------+--------+------+----------------+ +------+----------------+
* | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
* | 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
* +------+--------+------+----------------+ +------+----------------+
*
* @see LengthFieldPrepender
*/
public class LengthFieldBasedFrameDecoder extends ByteToMessageDecoder {
private final ByteOrder byteOrder;
private final int maxFrameLength;
private final int lengthFieldOffset;
private final int lengthFieldLength;
private final int lengthFieldEndOffset;
private final int lengthAdjustment;
private final int initialBytesToStrip;
private final boolean failFast;
private boolean discardingTooLongFrame;
private long tooLongFrameLength;
private long bytesToDiscard;
/**
* Creates a new instance.
*
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength) {
this(maxFrameLength, lengthFieldOffset, lengthFieldLength, 0, 0);
}
/**
* Creates a new instance.
*
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
* @param lengthAdjustment
* the compensation value to add to the value of the length field
* @param initialBytesToStrip
* the number of first bytes to strip out from the decoded frame
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip) {
this(
maxFrameLength,
lengthFieldOffset, lengthFieldLength, lengthAdjustment,
initialBytesToStrip, true);
}
/**
* Creates a new instance.
*
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
* @param lengthAdjustment
* the compensation value to add to the value of the length field
* @param initialBytesToStrip
* the number of first bytes to strip out from the decoded frame
* @param failFast
* If true, a {@link TooLongFrameException} is thrown as
* soon as the decoder notices the length of the frame will exceed
* maxFrameLength regardless of whether the entire frame
* has been read. If false, a {@link TooLongFrameException}
* is thrown after the entire frame that exceeds maxFrameLength
* has been read.
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength, int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
this(
ByteOrder.BIG_ENDIAN, maxFrameLength, lengthFieldOffset, lengthFieldLength,
lengthAdjustment, initialBytesToStrip, failFast);
}
/**
* Creates a new instance.
*
* @param byteOrder
* the {@link ByteOrder} of the length field
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
* @param lengthAdjustment
* the compensation value to add to the value of the length field
* @param initialBytesToStrip
* the number of first bytes to strip out from the decoded frame
* @param failFast
* If true, a {@link TooLongFrameException} is thrown as
* soon as the decoder notices the length of the frame will exceed
* maxFrameLength regardless of whether the entire frame
* has been read. If false, a {@link TooLongFrameException}
* is thrown after the entire frame that exceeds maxFrameLength
* has been read.
*/
public LengthFieldBasedFrameDecoder(
ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
if (byteOrder == null) {
throw new NullPointerException("byteOrder");
}
if (maxFrameLength ) {
throw new IllegalArgumentException(
"maxFrameLength must be a positive integer: " +
maxFrameLength);
}
if (lengthFieldOffset ) {
throw new IllegalArgumentException(
"lengthFieldOffset must be a non-negative integer: " +
lengthFieldOffset);
}
if (initialBytesToStrip ) {
throw new IllegalArgumentException(
"initialBytesToStrip must be a non-negative integer: " +
initialBytesToStrip);
}
if (lengthFieldOffset > maxFrameLength - lengthFieldLength) {
throw new IllegalArgumentException(
"maxFrameLength (" + maxFrameLength + ") " +
"must be equal to or greater than " +
"lengthFieldOffset (" + lengthFieldOffset + ") + " +
"lengthFieldLength (" + lengthFieldLength + ").");
}
this.byteOrder = byteOrder;
this.maxFrameLength = maxFrameLength;
this.lengthFieldOffset = lengthFieldOffset;
this.lengthFieldLength = lengthFieldLength;
this.lengthAdjustment = lengthAdjustment;
lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength;
this.initialBytesToStrip = initialBytesToStrip;
this.failFast = failFast;
}
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
if (discardingTooLongFrame) {
discardingTooLongFrame(in);
}
if (in.readableBytes() lengthFieldEndOffset) {
return null;
}
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
if (frameLength ) {
failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset);
}
frameLength += lengthAdjustment + lengthFieldEndOffset;
if (frameLength lengthFieldEndOffset) {
failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset);
}
if (frameLength > maxFrameLength) {
exceededFrameLength(in, frameLength);
return null;
}
// never overflows because it‘s less than maxFrameLength
int frameLengthInt = (int) frameLength;
if (in.readableBytes() frameLengthInt) {
return null;
}
if (initialBytesToStrip > frameLengthInt) {
failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip);
}
in.skipBytes(initialBytesToStrip);
// extract frame
int readerIndex = in.readerIndex();
int actualFrameLength = frameLengthInt - initialBytesToStrip;
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}
public class MessageEncoder extends ByteToMessageDecoder {
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf buffer, List
public void start() throws Exception {
new Thread(new Runnable() {
@Override
public void run() {
EventLoopGroup group = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap sb = new ServerBootstrap();
sb.group(group, workerGroup) // 绑定线程池
.channel(NioServerSocketChannel.class) // 指定使用的channel
.localAddress(port)// 绑定监听端口
.childHandler(new ChannelInitializer
475831393530303810d901000069da
文章标题:(一) netty 拆包,粘包处理(自定义协议)
文章链接:http://soscw.com/index.php/essay/60256.html