python-word2vec学习
2021-03-09 23:27
标签:dir rgba 通过 pat win white 必须 ini mat 一、数据预处理----sentence sentences是训练所需材料,可通过两种格式载入: 2、list嵌套格式 3、单个文件的导入 4、目录下所有文件有效 方法一: 方法二: Example: The files in the directory should be either text files, .bz2 files, or .gz files. 该路径下的文件 只有后缀为bz2,gz和text的文件可以被读取,其他的文件都会被认为是text文件 一个句子即一行,单词需要预先使用空格分隔 源处填写的必须是一个目录,务必保证该目录下的文件都能被该类读取。如果设置了读取限制,那么只读取限定的行数。 目录下的文件应该是如此种种。 二、模型生成和保存 其中:sg=1是skip—gram算法,对低频词敏感,默认sg=0为CBOW算法 size是神经网络层数,值太大则会耗内存并使算法计算变慢,一般值取为100到200之间 window是句子中当前词与目标词之间的最大距离,3表示在目标词前看3-b个词,后面看b个词(b在0-3之间随机) min_count是对词进行过滤,频率小于min-count的单词则会被忽视,默认值为5 negative和sample可根据训练结果进行微调,sample表示更高频率的词被随机下采样到所设置的阈值,默认值为1e-3 negative: 如果>0,则会采用negativesamping,用于设置多少个noise words hs=1表示层级softmax将会被使用,默认hs=0且negative不为0,则负采样将会被选择使用 workers是线程数,此参数只有在安装了Cpython后才有效,否则只能使用单核 model.wv.save_word2vec_format() 也能通过设置binary是否保存为二进制文件。但该模型在保存时丢弃了树的保存形式(详情参加word2vec构建过程,以类似哈夫曼树的形式保存词),所以在后续不能对模型进行追加训练 三、模型的加载 四、模型的追加训练 如果对..wv.save_word2vec_format()加载的模型进行追加训练,会报错: 五、模型的输出 python-word2vec学习 标签:dir rgba 通过 pat win white 必须 ini mat 原文地址:https://www.cnblogs.com/z-712/p/14162837.html
1、文本格式:
将每篇文章 分词去停用词后,用空格分割,将其存入txt文本中(每一行一篇文章)
将每篇文章 分词去停用词后,存入list中。
即[ [第一篇文章分词结果] , [第二篇文章分词结果], …] ,这里注意sentences 只是一个list,当其为文件的时候,不是这样引入文件的from gensim.models import Word2Vec
sentences = [["粉", "砂锅土豆粉", "砂锅米线"], ["肉", "鸡腿", "炸鸡排"]]
model = Word2Vec(sentences, min_count=1)
reviews = word2vec.LineSentence("dataset/totalFenci.txt")
class MySentences(object):
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
for fname in os.listdir(self.dirname):
for line in open(os.path.join(self.dirname, fname)):
yield line.split()
sentences = MySentences(‘/some/directory‘) # a memory-friendly iterator
model = gensim.models.Word2Vec(sentences)
gensim.models.word2vec.PathLineSentences(source, max_sentence_length=10000, limit=None)
sentences = PathLineSentences(path)
model=gensim.models.Word2Vec(sentences,sg=1,size=100,window=5,min_count=2,negative=3,sample=0.001,hs=1,workers=4)
model.save("文本名") #模型会保存到该 .py文件同级目录下,该模型打开为乱码
#model.wv.save_word2vec_format("文件名",binary = "Ture/False") #通过该方式保存的模型,能通过文本格式打开
# `.save`保存的模型的加载:
gensim.models.Word2Vec.load("模型文件名")
#`..wv.save_word2vec_format`保存的模型的加载:
model = model.wv.load_word2vec_format(‘模型文件名‘)
model.train(more_sentences)
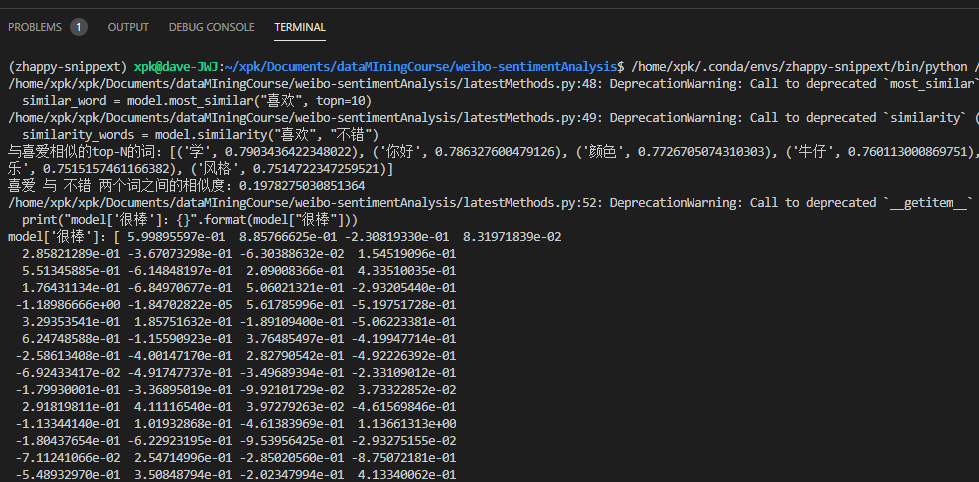
AttributeError: ‘Word2VecKeyedVectors‘ object has no attribute ‘train‘,原因前面提及过了。model = word2vec.Word2Vec.load("dataset/dic/word2vector.model")
similar_word = model.most_similar("喜欢", topn=10)
similarity_words = model.similarity("喜欢", "不错")
print("与喜爱相似的top-N的词:{}".format(similar_word))
print("喜爱 与 不错 两个词之间的相似度:{}".format(similarity_words))
print("model[‘很棒‘]:{}".format(model["很棒"]))
上一篇:子线程适当Sleep的重要性