DirectX11 With Windows SDK--30 计算着色器:图像模糊、索贝尔算子
2021-03-20 02:26
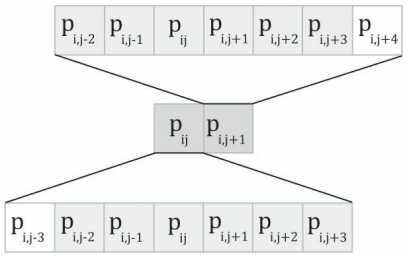
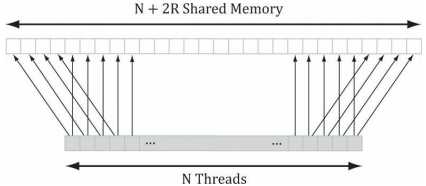
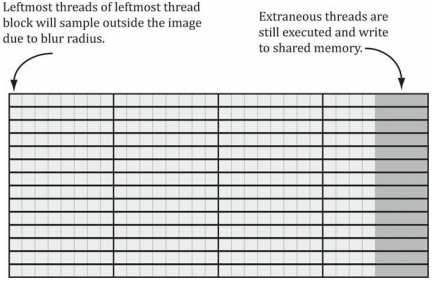
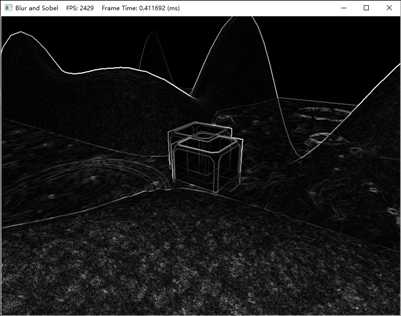
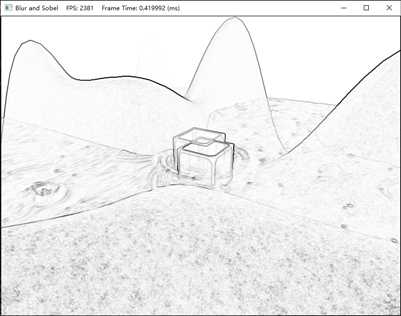
标签:结果 正态分布 gpu osi level code tcl 过滤 带宽 到这里计算着色器的主线学习基本结束,剩下的就是再补充两个有关图像处理方面的应用。这里面包含了龙书11的图像模糊,以及龙书12额外提到的Sobel算子进行边缘检测。主要内容源自于龙书12,项目源码也基于此进行调整。 学习目标: DirectX11 With Windows SDK完整目录 Github项目源码 欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。 在图像处理中,经常需要用到卷积,很多效果都能够通过卷积的形式来实现。针对源图像中的每一个像素\(P_{ij}\),计算以它为中心的m×n矩阵的加权值。此加权值便是经过处理后图像中第i行、第j列的颜色,如果写成卷积的形式则为: 在保证权值和为1的前提下,我们就能用多种不同的方法来计算它。其中就有一种广为人知的模糊运算:高斯模糊(Gaussian blur)。该算法借助高斯函数\(G(x)=exp(-\frac{x^2}{2\sigma^2})\)来获取权值。下图展示了取不同σ值时高斯函数的对应图像: 可以看到,若σ越大,则曲线越趋于平缓,给邻近点所赋予的权值也就越大。 现在假设我们要进行规模为1×5的高斯模糊(即在水平方向进行1D模糊),且设σ=1。分别对x=-2,-1,0,1,2求G(x)的值,可以得到: 因此有: 首先,假设所运用的模糊算法具有可分离性,据此将模糊操作分为两个1D模糊运算:一个横向模糊运算,一个纵向模糊运算。假定用户提供了一个纹理A作为输入(通常是作为SRV形参),以及一个纹理B作为输出(通常是作为UAV形参)。不过要考虑到有的用户希望将直接修改纹理A,将纹理A的SRV和UAV都传入。因此我们还是需要两个存储中间结果的纹理T0、T1,过程如下: 由于渲染到纹理种的场景于窗口工作区要保持着相同的分辨率,我们需要不时重新构建离屏纹理,而模糊算法用的临时纹理T也是如此。在 假如要处理的图像宽度为w、宽度为h。对于1D纵向模糊而言,一个线程组用256个线程来处理水平方向上的线段,而且每个线程又负责图像中一个像素的模糊操作。因此,为了图像中的每个像素都能得到模糊处理,我们需要在x方向上调度\(ceil(\frac{w}{256})\)个线程组(ceil为上取整函数),且在y方向上调度h个线程组。如果w不能被256整除,则最后一次调度的线程组会存有多余的线程(见下图)。我们对于这种情况无能为力,因为线程组的大小固定。因此,我们只得把注意力放在着色器代码中越界问题的钳位检测(clamping check)上。 1D纵向模糊于上述1D横向模糊的情况相似。在纵向模糊过程中,线程组就像由256个线程构成的垂直线段,每个线程只负责图像中一个像素的模糊运算。因此,为了使图像中的每个像素都能得到模糊处理,我们需要在y方向上调度\(ceil(\frac{h}{256})\)个线程组,并在x方向上调度w个线程组。 现在来考虑对一个28x14像素的纹理进行处理,我们所用的横向、纵向线程组的规模分别为8x1和1x8(采用X×Y的表示格式)。对于水平方向的处理过程来说,为了处理所有的像素,我们需要在x方向上调度\(ceil(\frac{w}{8})=ceil(\frac{28}{8})=4\)个线程组,并在y方向上调度14个线程组。由于28并不能被8整除,所以最右侧的线程组中会有\((4\times 8-28)\times 14=56\)个线程声明都不做。对于垂直方向的处理过程而言,为了处理所有的像素,我们需要在y方向上分派\(ceil(\frac{h}{8})=ceil(\frac{14}{8})=2\)个线程组,并在x方向上调度28个线程组。同理,由于14并不能被8整除,所以最下侧的线程组中会有\((2\times 8 - 14)\times 28\)个闲置的线程。沿用同一思路就可以将线程组扩展为256个线程的规模来处理更大的纹理。 其余C++端源码则直接去项目源码看即可。 由于水平模糊与垂直模糊的实现原理相仿,这里我们只讨论水平模糊。 在上面的代码中,我们可以看到调度的线程组是由256个线程构成的水平“线段”,每个线程都负责图像中一个像素的模糊操作。一种低效的实现方案是,每个线程都简单地计算出以正在处理的像素为中心的行矩阵(因为我们现在正在进行的是1D横向模糊处理,所以要针对行矩阵进行计算)的加权平均值。这种办法的缺点是需要多次拾取同一纹素。 仅考虑输入图像中的这两个相邻像素,假设模糊核为1×7。光是在对这两个像素进行模糊的过程中,8个不同的像素中就已经有6个被采集了2次,而且要考虑到访问设备内存的效率在GPU内存模型中是属于比较慢的一种。 我们可以根据前面一节提到的模糊处理策略,利用共享内存来优化上述算法。这样一来,每个线程就可以在共享内存中读取或存储所需的纹素数据。待所有线程都从共享内存读取到它们所需的纹素后,就能够执行模糊运算了。不得不说,从共享内存中读取数据的速度飞快。除此之外,还有一件棘手的事情,就是利用具有n = 256个线程的线程组行模糊运算的时候,却需要n + 2R个纹素数据,这里的R就是模糊半径: 由于模糊半径的原因,在处理线程组边界附近的像素时,可能会读取线程组以外存在“越界”情况的像素。解决办法其实也并不复杂。我们只需要分配出能容纳n + 2R个元素的共享内存,并且有2R个线程要各获取两个纹素数据。唯一麻烦的地方就是在共享内存时要多花心思,因为组内线程ID此时不能于共享内存中的元素一一对应了。下图演示了当R=4时,从线程到共享内存的映射过程。 在此例中,R = 4。最左侧的4个线程以及最右侧的4个线程,每个都要读取2个纹素数据,并将它们存于共享内存之中。而这8个线程之外的所有线程都只需要读取1个像素,并将其存于共享内存之中。这样一来,我们即可以得到以模糊半径R对N个像素进行模糊处理所需的所有纹素数据。 现在要讨论的是最后一种情况,即下图中所示的最左侧于最右侧的线程组在索引输入图像时会发生越界的情形。 前面提到,从越界的索引处读取数据并不是非法操作,而是返回0(对越界索引处进行写入是不会执行任何操作的,即no-op)。然而,我们在读取越界数据时并不希望得到数据0,因为这意味着值为0的颜色(即黑色)会影响到边界处的模糊结果。我们此时期盼能实现出类似于钳位(clamp)纹理寻址模式的效果,即在读取越界的数据时,能够获得一个与边界纹素相同的数据。这个方案可以通过对索引进行钳位来加以实现,在下面完整的着色器代码可以看到(这里将模糊半径调大了): 最右侧的线程组可能存有一些多余的线程,但输出的纹理中并没有与之对应的元素(意味着它们根本无需输出任何数据,见上图)。此时 索贝尔算子(Sobel Operator)用于图像的边缘检测。它会针对每一个像素估算其梯度(gradient)的大小。梯度值较大的像素则表明它与周围像素的颜色差异极大,因而此像素一定位于图像的边缘。相反,具有较小梯度的像素则意味着它与临近像素的颜色趋同,即该像素并不处于图像边沿之上。需要注意的是,索贝尔算子返回的并非是像素是否位于图像边缘的二元结果,而是一个范围在[0.0, 1.0]内表示边缘“陡峭”程度的灰度值:值为0表示非常平坦,与周围像素并没有颜色差异;值为1表示非常陡峭,与周围像素颜色差异很大。通常索贝尔逆图像(1-c)往往会更加直观有效,这时白色表示平坦且不位于图像边缘,而黑色则代表陡峭且处于图像边缘。 运用索贝尔算子后的结果: 索贝尔算子的逆图像的结果: 如果将原始图像与其经过索贝尔算子生成的逆图像两者间的对应颜色值相乘,我们将获得类似于卡通画或动漫书中那样,其边缘就像用黑色的笔勾描后的图片效果。哪怕待处理的图像首先经过模糊处理后已经隐去了部分细节,依旧可以恢复其相对粗犷的画风,令其边缘清晰起来。 索贝尔算子所采用的算法是先进行加权平均,然后进行近似求导运算,计算方法如下: 因此我们就得到了梯度向量\((\Delta_x f(x, y), \Delta_y f(x, y))\),然后求出它的长度\(\parallel \sqrt{G_{x}^{2} + G_{y}^{2}}\parallel\)即为变化方向最大处的变化率。 索贝尔算子的HLSL代码实现如下: 在C++端的代码可以直接去源码中寻找 本样例为高斯模糊提供了调整模糊半径、Sigma和次数的功能。模糊半径越大,模糊次数越大,帧数会越低。如果你的电脑配置承受不住,建议关掉OIT来观察模糊效果会更好一些。至于Sobel算子则无法调整。 整个计算着色器的内容就到此结束了。 该项目无法图形调试,就和DirectX SDK Samples中OIT样例一样,遇到了未知问题。如果要调试,需要把OIT相关的代码撤走才能调试。 此外,龙书12中的 对图像进行模糊处理是一种昂贵的操作,它所花费的时间于待处理的图像大小息息相关。一般情况下,在把场景渲染到离屏纹理的时候,我们通常会将离屏纹理的大小设为后备缓冲区尺寸的1/4.也就是说,假如后备缓冲区的大小为800x600,则离屏纹理的尺寸将为400x300.这样一来不仅能加快离屏纹理的绘制速度(即减少了需要填充的像素数量),而且能同时提升模糊图像的处理速度(需要模糊的像素也就更少)。另外,当纹理从1/4的屏幕分辨率拉伸为完整大屏幕分辨率时,纹理放大过滤器也会执行一些额外的模糊操作。 研究双边模糊(双边滤波器,bilateral blur)计数,并用计算着色器加以实现。 DirectX11 With Windows SDK完整目录 Github项目源码 欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。 DirectX11 With Windows SDK--30 计算着色器:图像模糊、索贝尔算子 标签:结果 正态分布 gpu osi level code tcl 过滤 带宽 原文地址:https://www.cnblogs.com/X-Jun/p/12309749.html前言
图像卷积
\[
H_{ij}=\sum_{r=-a}^{a}\sum_{c=-b}^{b}W_{rc}P_{i-r,j-c}
\]
其中,\(m=2a+1\)且\(n=2b+1\),将m与n强制为奇数,以此来保证m×n矩阵总是具有“中心”项。若a=b=r,则只需指定半径r就可以确定矩阵的大小。\(W_{rc}\)为m×n矩阵(又称内核、算子)中的权值。为了方便观察计算及编码,通常会将内核旋转180°,这样就得到了更加常用的计算公式:
\[
H_{ij}=\sum_{r=-a}^{a}\sum_{c=-b}^{b}W_{rc}P_{i+r,j+c}
\]
若内核的所有权值的和为1,则它可以用来做模糊处理;如果权值和大于0小于1,则处理后的图像会随着颜色的缺失而变暗;如果权值和大于1,则处理后的图像会随着颜色的增添而更加明亮。当然也会有权值和等于0甚至可能小于0的情况,比如索贝尔算子。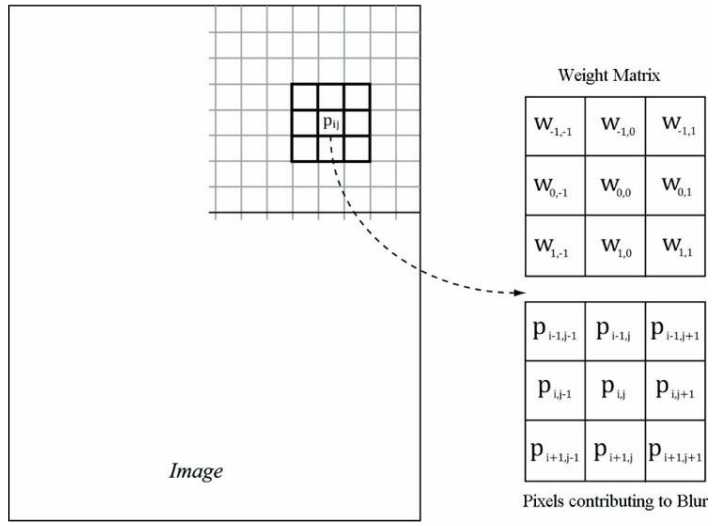
图像模糊
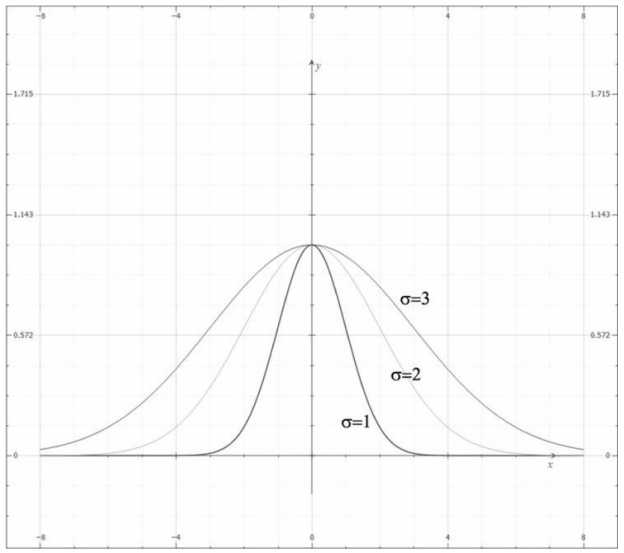
\[
G(x)=exp(-\frac{x^2}{2\sigma^2})=e^{-\frac{x^2}{2\sigma^2}}
\]
如果学过概率论的话应该知道它很像标准正态分布的概率密度,只不过缺了一个系数\(\frac{1}{\sqrt{2\pi}\;\sigma}\)。
\[
\begin{align}G(-2)&=exp(-\frac{(-2)^2}{2})=e^{-2} \\G(-1)&=exp(-\frac{(-1)^2}{2})=e^{-\frac{1}{2}} \\G(0)&=exp(0)=1 \\G(1)&=exp(-\frac{1^2}{2})=e^{-\frac{1}{2}} \\G(2)&=exp(-\frac{2^2}{2})=e^{-2}\end{align}
\]
但是,这些数据还不是最终的权值,因为它们的和不为1:
\[
\begin{align}
\sum_{x=-2}^{x=2}G(x)&=G(-2)+G(-1)+G(0)+G(1)+G(2)\&=1+2e^{-\frac{1}{2}}+2e^{-2}\&\approx 2.48373
\end{align}
\]
如果将前面5个值都除以它们的和进行规格化处理,那么我们便会基于高斯函数获得总和为1的各个权值:
\[
\begin{align}
w_{-2}&=\frac{G(-2)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.0545\w_{-1}&=\frac{G(-1)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.2442\w_{0}&=\frac{G(0)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.4026\w_{1}&=\frac{G(1)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.2442\w_{2}&=\frac{G(2)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.0545\\end{align}
\]
对于二维的高斯函数,有
\[
\begin{align}
G(x, y) &= G(x)\cdot G(y) \&=exp(-\frac{x^2}{2\sigma^2})\cdot exp(-\frac{x^2}{2\sigma^2}) \&=e^{-\frac{x^2+y^2}{2\sigma^2}}
\end{align}
\]
假如我们要进行3x3的高斯模糊,且设σ=1,则未经过归一化的内核为:
\[
\begin{bmatrix}
G(-1)G(-1) & G(-1)G(0) & G(-1)G(1) \G(0)G(-1) & G(0)G(0) & G(0)G(1) \G(1)G(-1) & G(1)G(0) & G(1)G(1) \\end{bmatrix} = \begin{bmatrix}
G(-1) \G(0) \G(1) \\end{bmatrix}\begin{bmatrix}
G(-1) & G(0) & G(1) \\end{bmatrix}
\]
由于上面的内核矩阵可以写成一个列向量乘以一个行向量的形式,因此在做模糊的时候可以将一个2D模糊过程分为两个1D模糊过程。这也就说明该内核具有可分离性。
\[
Blur(I)=Blur_V(Blur_H(I))
\]
假如模糊核为一个9×9矩阵,我们就需要对总计81个样本依次进行2D模糊运算。但通过将模糊过程分离为两个1D模糊阶段,便仅需要处理9+9=18个样本!我们常常要对纹理进行模糊处理,而对纹理采样是代价高昂的操作。因此,通过分离模糊过程来减少纹理采样操作是一种受用户欢迎的优化手段。尽管有些模糊方法不具备可分离性,但只要保证最终图像在视觉上足够精准,我们往往还是能以优化性能为目的而简化其模糊过程。实现原理
GameApp::OnResize的时候重新调整即可。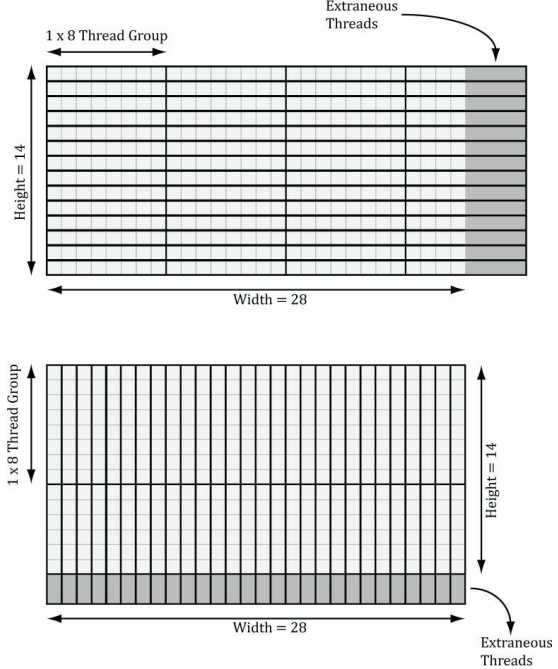
BlurFilter::Execute不仅计算出了每个方向要调度的线程组数量,还开启了计算着色器的模糊运算:void BlurFilter::Execute(ID3D11DeviceContext* deviceContext, ID3D11ShaderResourceView* inputTex, ID3D11UnorderedAccessView* outputTex, UINT blurTimes)
{
if (!deviceContext || !inputTex || !blurTimes)
return;
// 设置常量缓冲区
D3D11_MAPPED_SUBRESOURCE mappedData;
deviceContext->Map(m_pConstantBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData);
memcpy_s(mappedData.pData, sizeof m_CBSettings, &m_CBSettings, sizeof m_CBSettings);
deviceContext->Unmap(m_pConstantBuffer.Get(), 0);
deviceContext->CSSetConstantBuffers(0, 1, m_pConstantBuffer.GetAddressOf());
ID3D11UnorderedAccessView* nullUAV[1] = { nullptr };
ID3D11ShaderResourceView* nullSRV[1] = { nullptr };
// 第一次模糊
// 横向模糊
deviceContext->CSSetShader(m_pBlurHorzCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, &inputTex);
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV0.GetAddressOf(), nullptr);
deviceContext->Dispatch((UINT)ceilf(m_Width / 256.0f), m_Height, 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
// 纵向模糊
deviceContext->CSSetShader(m_pBlurVertCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, m_pTempSRV0.GetAddressOf());
if (blurTimes == 1 && outputTex)
deviceContext->CSSetUnorderedAccessViews(0, 1, &outputTex, nullptr);
else
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV1.GetAddressOf(), nullptr);
deviceContext->Dispatch(m_Width, (UINT)ceilf(m_Height / 256.0f), 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
// 剩余模糊次数
while (--blurTimes)
{
// 横向模糊
deviceContext->CSSetShader(m_pBlurHorzCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, m_pTempSRV1.GetAddressOf());
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV0.GetAddressOf(), nullptr);
deviceContext->Dispatch((UINT)ceilf(m_Width / 256.0f), m_Height, 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
// 纵向模糊
deviceContext->CSSetShader(m_pBlurVertCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, m_pTempSRV0.GetAddressOf());
if (blurTimes == 1 && outputTex)
deviceContext->CSSetUnorderedAccessViews(0, 1, &outputTex, nullptr);
else
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV1.GetAddressOf(), nullptr);
deviceContext->Dispatch(m_Width, (UINT)ceilf(m_Height / 256.0f), 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
}
// 解除剩余绑定
deviceContext->CSSetShaderResources(0, 1, nullSRV);
}HLSL代码

// Blur.hlsli
cbuffer CBSettings : register(b0)
{
int g_BlurRadius;
// 最多支持19个模糊权值
float w0;
float w1;
float w2;
float w3;
float w4;
float w5;
float w6;
float w7;
float w8;
float w9;
float w10;
float w11;
float w12;
float w13;
float w14;
float w15;
float w16;
float w17;
float w18;
}
Texture2D g_Input : register(t0);
RWTexture2D// Blur_Horz_CS.hlsl
#include "Blur.hlsli"
groupshared float4 g_Cache[CacheSize];
[numthreads(N, 1, 1)]
void CS(int3 GTid : SV_GroupThreadID,
int3 DTid : SV_DispatchThreadID)
{
// 放在数组中以便于索引
float g_Weights[19] =
{
w0, w1, w2, w3, w4, w5, w6, w7, w8, w9,
w10, w11, w12, w13, w14, w15, w16, w17, w18
};
// 通过填写本地线程存储区来减少带宽的负载。若要对N个像素进行模糊处理,根据模糊半径,
// 我们需要加载N + 2 * BlurRadius个像素
// 此线程组运行着N个线程。为了获取额外的2*BlurRadius个像素,就需要有2*BlurRadius个
// 线程都多采集一个像素数据
if (GTid.x = N - g_BlurRadius)
{
// 对于图像左侧边界存在越界采样的情况进行钳位(Clamp)操作
// 震惊的是Texture2D居然能通过属性Length访问宽高
int x = min(DTid.x + g_BlurRadius, g_Input.Length.x - 1);
g_Cache[GTid.x + 2 * g_BlurRadius] = g_Input[int2(x, DTid.y)];
}
// 将数据写入Cache的对应位置
// 针对图形边界处的越界采样情况进行钳位处理
g_Cache[GTid.x + g_BlurRadius] = g_Input[min(DTid.xy, g_Input.Length.xy - 1)];
// 等待所有线程完成任务
GroupMemoryBarrierWithGroupSync();
// 开始对每个像素进行混合
float4 blurColor = float4(0.0f, 0.0f, 0.0f, 0.0f);
for (int i = -g_BlurRadius; i Blur_Vert_CS.hlsl与上面的代码类似,就不再放出。DTid.xy即为输出纹理之外的一个越界索引。但是我们无需为此而担心,因为向越界处写入数据的效果是不进行任何操作(no-op)。索贝尔算子
\[
G_x = \Delta_x f(x, y) = [f(x-1,y+1)+2f(x,y+1)+f(x+1,y+1)]-[f(x-1,y-1)+2f(x,y-1)+f(x+1,y-1)] \G_y = \Delta_y f(x, y) = [f(x-1,y-1)+2f(x-1,y)+f(x-1,y+1)]-[f(x+1,y-1)+2f(x+1,y)+f(x+1,y+1)]
\]HLSL代码
// Sobel_CS.hlsl
Texture2D g_Input : register(t0);
RWTexture2D// VS使用Basic_VS_2D
// Composite_PS.hlsl
Texture2D g_BaseMap : register(t0); // 原纹理
Texture2D g_EdgeMap : register(t1); // 边缘纹理
SamplerState g_SamLinearWrap : register(s0); // 线性过滤+Wrap采样器
SamplerState g_SamPointClamp : register(s1); // 点过滤+Clamp采样器
float4 PS(float4 posH : SV_Position, float2 tex : TEXCOORD) : SV_Target
{
float4 c = g_BaseMap.SampleLevel(g_SamPointClamp, tex, 0.0f);
float4 e = g_EdgeMap.SampleLevel(g_SamPointClamp, tex, 0.0f);
// 将原始图片与边缘图相乘
return c * e;
}
SobelFilter。演示
调试问题

Composite.hlsl顶点着色器用到了SV_VertexID,一旦用了该系统值作为输入,就无法在最终结果选择像素观察运行过程了。因此本项目并没有使用内置于着色器的顶点数据。练习题
现在尝试修改项目,让BlurFilter的分辨率为400x300,实现上述内容。
提示:TextureRender开启mipmaps,并将mip等级为1的纹理作为SRV。Composite_VS.hlsl,将绘制整个屏幕的6个顶点直接放在顶点着色器中,然后只使用SV_VertexID作为顶点着色器的形参来绘制。
文章标题:DirectX11 With Windows SDK--30 计算着色器:图像模糊、索贝尔算子
文章链接:http://soscw.com/index.php/essay/66511.html