从头学pytorch(二十一):全连接网络dense net
2021-04-19 10:28
标签:lin 核数 降维 ide 目的 测试 ram 连接 flatten 论文传送门,这篇论文是CVPR 2017的最佳论文. resnet一文里说了,resnet是具有里程碑意义的.densenet就是受resnet的启发提出的模型. resnet中是把不同层的feature map相应元素的值直接相加.而densenet是将channel维上的feature map直接concat在一起,从而实现了feature的复用.如下所示: 首先实现DenseBlock bottleneck layer growth rate conv 首先是1x1卷积,然后是3x3卷积.3x3卷积核的数量即growth_rate,bottleneck_size即1x1卷积核数量.论文里是bottleneck_size=4xgrowth_rate的关系. 注意forward函数的实现 我们传进来的是一个元祖,其含义是[block的输入,layer1输出,layer2输出,...].前面说过了,一个dense block内的每一个layer的输入是前面所有layer的输出和该block的输入在channel维度上的连接.这样就使得不同layer的feature map得到了充分的利用. tips: 一个Dense Block由多个Layer组成.这里注意forward的实现,init_features即该block的输入,然后每个layer都会得到一个输出.第n个layer的输入由输入和前n-1个layer的输出在channel维度上连接组成. 最后,该block的输出为各个layer的输出为输入以及各个layer的输出在channel维度上连接而成. 很显然,dense block的计算方式会使得channel维度过大,所以每一个dense block之后要通过1x1卷积在channel维度降维. dense net的基本组件我们已经实现了.下面就可以实现dense net了. 首先和resnet一样,首先是7x7卷积接3x3,stride=2的最大池化,然后就是不断地dense block + tansition.得到feature map以后用全局平均池化得到n个feature.然后给全连接层做分类使用. 可以用 测试一下,输出如下,可以看出feature map的变化情况.最终得到508x7x7的feature map.全局平均池化后,得到508个特征,通过线性回归得到10个类别. 总结: 从头学pytorch(二十一):全连接网络dense net 标签:lin 核数 降维 ide 目的 测试 ram 连接 flatten 原文地址:https://www.cnblogs.com/sdu20112013/p/12269817.htmlDenseNet
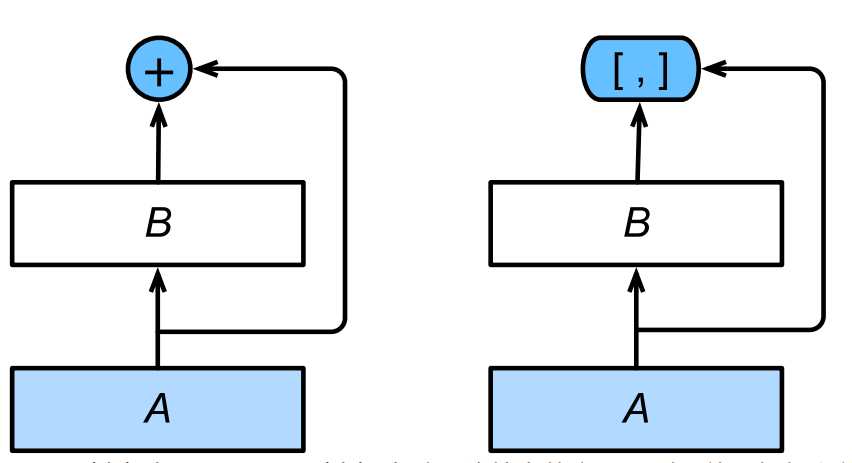

注意,是连接dense block内输出层前面所有层的输出,不是只有输出层的前一层网络结构

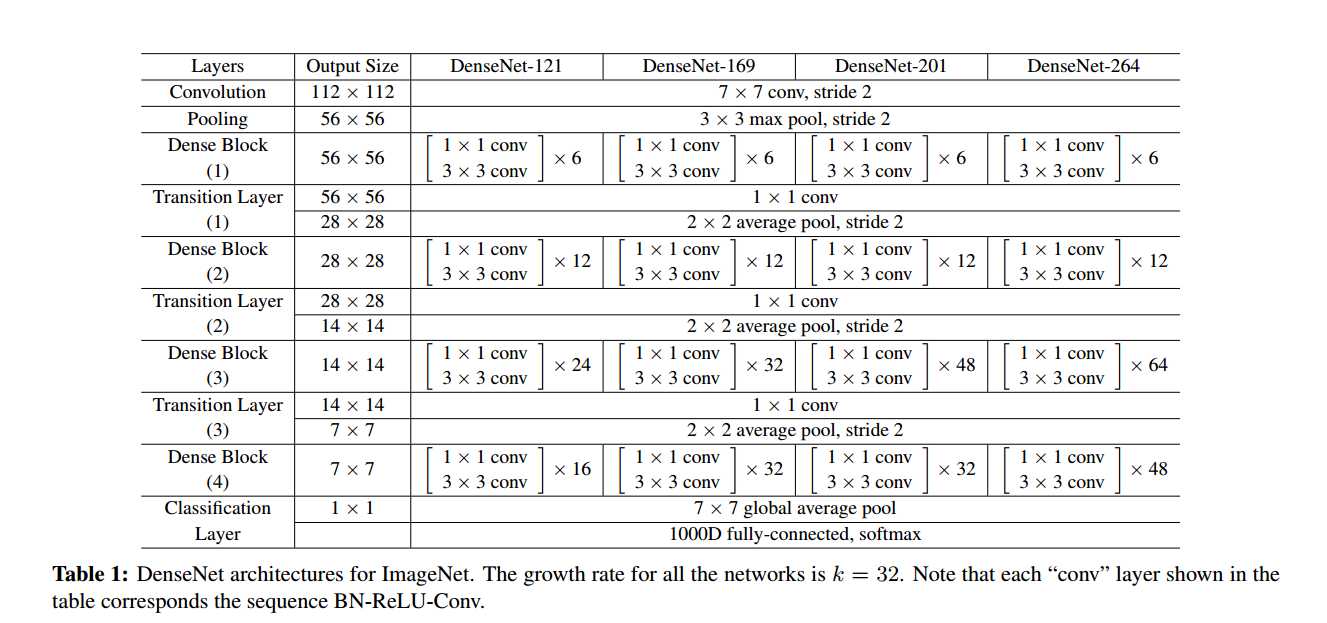
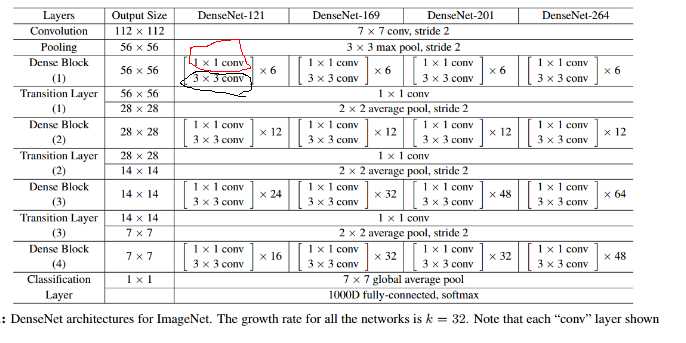
先解释几个名词
即上图中红圈的1x1卷积核.主要目的是对输入在channel维度做降维.减少运算量.
卷积核的数量为4k,k为该layer输出的feature map的数量(也就是3x3卷积核的数量)
即上图中黑圈处3x3卷积核的数量.假设3x3卷积核的数量为k,则每个这种3x3卷积后,都得到一个channel=k的输出.假如一个denseblock有m组这种结构,输入的channel为n的话,则做完一次连接操作后得到的输出的channel为n + k + k +...+k = n+m*k.所以又叫做growth rate.
论文里的conv指的是BN-ReLU-Conv实现DenseBlock
DenseLayer
class DenseLayer(nn.Module):
def __init__(self,in_channels,bottleneck_size,growth_rate):
super(DenseLayer,self).__init__()
count_of_1x1 = bottleneck_size
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu1 = nn.ReLU(inplace=True)
self.conv1x1 = nn.Conv2d(in_channels,count_of_1x1,kernel_size=1)
self.bn2 = nn.BatchNorm2d(count_of_1x1)
self.relu2 = nn.ReLU(inplace=True)
self.conv3x3 = nn.Conv2d(count_of_1x1,growth_rate,kernel_size=3,padding=1)
def forward(self,*prev_features):
# for f in prev_features:
# print(f.shape)
input = torch.cat(prev_features,dim=1)
# print(input.device,input.shape)
# for param in self.bn1.parameters():
# print(param.device)
# print(list())
bottleneck_output = self.conv1x1(self.relu1(self.bn1(input)))
out = self.conv3x3(self.relu2(self.bn2(bottleneck_output)))
return out def forward(self,*prev_features):
# for f in prev_features:
# print(f.shape)
input = torch.cat(prev_features,dim=1)
# print(input.device,input.shape)
# for param in self.bn1.parameters():
# print(param.device)
# print(list())
bottleneck_output = self.conv1x1(self.relu1(self.bn1(input)))
out = self.conv3x3(self.relu2(self.bn2(bottleneck_output)))
return out
函数参数带*表示可以传入任意多的参数,这些参数被组织成元祖的形式,比如## var-positional parameter
## 定义的时候,我们需要添加单个星号作为前缀
def func(arg1, arg2, *args):
print arg1, arg2, args
## 调用的时候,前面两个必须在前面
## 前两个参数是位置或关键字参数的形式
## 所以你可以使用这种参数的任一合法的传递方法
func("hello", "Tuple, values is:", 2, 3, 3, 4)
## Output:
## hello Tuple, values is: (2, 3, 3, 4)
## 多余的参数将自动被放入元组中提供给函数使用
## 如果你需要传递元组给函数
## 你需要在传递的过程中添加*号
## 请看下面例子中的输出差异:
func("hello", "Tuple, values is:", (2, 3, 3, 4))
## Output:
## hello Tuple, values is: ((2, 3, 3, 4),)
func("hello", "Tuple, values is:", *(2, 3, 3, 4))
## Output:
## hello Tuple, values is: (2, 3, 3, 4)DenseBlock
class DenseBlock(nn.Module):
def __init__(self,in_channels,layer_counts,growth_rate):
super(DenseBlock,self).__init__()
self.layer_counts = layer_counts
self.layers = []
for i in range(layer_counts):
curr_input_channel = in_channels + i*growth_rate
bottleneck_size = 4*growth_rate #论文里设置的1x1卷积核是3x3卷积核的4倍.
layer = DenseLayer(curr_input_channel,bottleneck_size,growth_rate).cuda()
self.layers.append(layer)
def forward(self,init_features):
features = [init_features]
for layer in self.layers:
layer_out = layer(*features) #注意参数是*features不是features
features.append(layer_out)
return torch.cat(features, 1)TransitionLayer
class TransitionLayer(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(TransitionLayer, self).__init__()
self.add_module('norm', nn.BatchNorm2d(in_channels))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(in_channels, out_channels,kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
Dense Net
class DenseNet(nn.Module):
def __init__(self,in_channels,num_classes,block_config):
super(DenseNet,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.pool1 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.dense_block_layers = nn.Sequential()
block_in_channels = in_channels
growth_rate = 32
for i,layers_counts in enumerate(block_config):
block = DenseBlock(in_channels=block_in_channels,layer_counts=layers_counts,growth_rate=growth_rate)
self.dense_block_layers.add_module('block%d' % (i+1),block)
block_out_channels = block_in_channels + layers_counts*growth_rate
transition = TransitionLayer(block_out_channels,block_out_channels//2)
if i != len(block_config): #最后一个dense block后没有transition layer
self.dense_block_layers.add_module('transition%d' % (i+1),transition)
block_in_channels = block_out_channels // 2 #更新下一个dense block的in_channels
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=(1,1))
self.fc = nn.Linear(block_in_channels,num_classes)
def forward(self,x):
out = self.conv1(x)
out = self.pool1(x)
for layer in self.dense_block_layers:
out = layer(out)
# print(out.shape)
out = self.avg_pool(out)
out = torch.flatten(out,start_dim=1) #相当于out = out.view((x.shape[0],-1))
out = self.fc(out)
return outX=torch.randn(1,3,224,224).cuda()
block_config = [6,12,24,16]
net = DenseNet(3,10,block_config)
net = net.cuda()
out = net(X)
print(out.shape)torch.Size([1, 195, 112, 112])
torch.Size([1, 97, 56, 56])
torch.Size([1, 481, 56, 56])
torch.Size([1, 240, 28, 28])
torch.Size([1, 1008, 28, 28])
torch.Size([1, 504, 14, 14])
torch.Size([1, 1016, 14, 14])
torch.Size([1, 508, 7, 7])
torch.Size([1, 10])
核心就是dense block内每一个layer都复用了之前的layer得到的feature map,因为底层细节的feature被复用,所以使得模型的特征提取能力更强. 当然坏处就是计算量大,显存消耗大.
文章标题:从头学pytorch(二十一):全连接网络dense net
文章链接:http://soscw.com/index.php/essay/76620.html