python爬虫详细解析附案例
2021-05-08 19:30
标签:iter encoding 取出 打开 his error: image pycha aio 什么是爬虫框架 说这个之前,得先说说什么是框架: 框架的关注点在于规范二字,好,我们要写的Python爬虫框架规范是什么? 很简单,爬虫框架就是对爬虫流程规范的实现,不清楚的朋友可以看上一篇文章谈谈对Python爬虫的理解,下面总结一下爬虫流程: 这三个流程有没有可能以一种优雅的形式串联起来, 可以看到, 实现了基本流程规范之后,我们继而就可以考虑一些基础功能,让使用者编写爬虫可以更加轻松,比如:中间件(Ruia里面的Middleware)、提供一些 这些想明白之后,接下来就可以愉快地编写自己心目中的爬虫框架了 首先,我对Ruia爬虫框架的定位很清楚,基于 什么是爬虫框架如今我们已经很清楚了,现在急需要做的就是将流程规范利用Python语言实现出来,怎么实现,分为哪几个模块,可以看如下图示: ? 同时让我们结合上面一节的 这四个部分我们可以简单地使用五个类来实现,在开始讲解之前,请先克隆 然后用 选择刚刚 此时可以完整地看到项目代码: 好,环境以及源码准备完毕,接下来将结合代码讲述一个爬虫框架的编写流程 接下来就简单了,不过就是实现上述需求,首先,需要实现一个函数来抓取目标 实际运行一下,会输出请求状态 最终代码见 这段代码请求了目标网页 实现了对目标网页的请求,接下来就是对目标网页进行字段提取,我觉得 可能说起来比较拗口,下面直接演示一下可能你就明白这样写的好,假设你的需求是获取 从输出结果可以看到, 来看看怎么实现, 所以我们只需要根据需求,定义父类然后再利用不同的提取方式实现子类即可,代码如下: 核心类就是上面的代码,具体实现请看 接下来继续说 这一层弄明白接下来就很简单了,还记得上一篇文章《谈谈对Python爬虫的理解》里面说的四个类型的目标网页么: 本质来说就是要获取网页的单目标以及多目标(多页面可以放在Spider那块实现), 具体实现见: 在 接下来说说代码实现, 使用起来还是挺简洁的,输出如下: 详细代码,见 至此,爬虫框架的核心部分已经实现完毕,基础功能同样一个不落地实现了,接下来要做的就是: 更多推荐: https://www.cnblogs.com/leetcodetijie/p/13175504.html python爬虫详细解析附案例 标签:iter encoding 取出 打开 his error: image pycha aio 原文地址:https://www.cnblogs.com/leetcodetijie/p/13175528.html
MVC开发规范Django框架就是MVC的开发框架,但它还提供了其他基础功能帮助我们快速开发,比如中间件、认证系统等
Ruia目前是这样实现的,请看代码示例: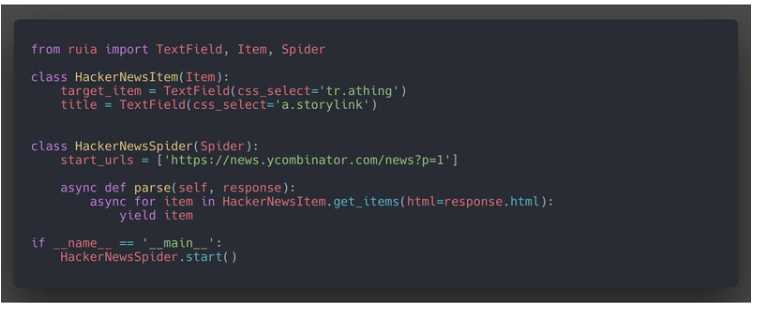
Item & Field类结合一起实现了字段的解析提取,Spider类结合Request * Response类实现了对爬虫程序整体的控制,从而可以如同流水线一般编写爬虫,最后返回的item可以根据使用者自身的需求进行持久化,这几行代码,我们就实现了获取目标网页请求、字段解析提取、持久化这三个流程hook让用户编写爬虫更方便(比如ruia-motor)如何踏出第一步
asyncio & aiohttp的一个轻量的、异步爬虫框架,怎么实现呢,我觉得以下几点需要遵守:
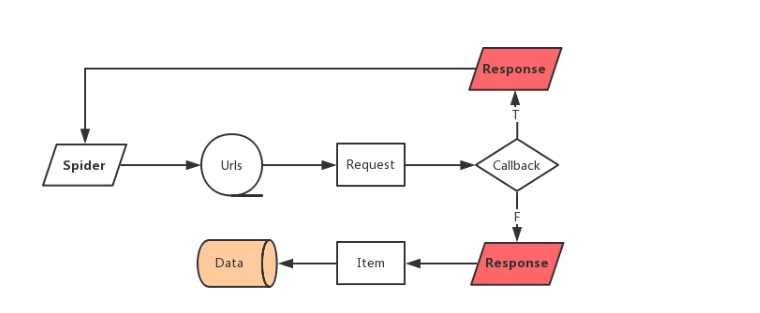
Ruia代码来从业务逻辑角度看看这几个模块到底是什么意思:
Ruia框架到本地:# 请确保本地Python环境是3.6+
git clone https://github.com/howie6879/ruia.git
# 安装pipenv
pip install pipenv
# 安装依赖包
pipenv install --devPyCharm打开Ruia项目:
pipenv配置好的python解释器:
Request & Response
Request类的目的是对aiohttp加一层封装进行模拟请求,功能如下:
Response类返回url,比如命名为fetch:import asyncio
import aiohttp
import async_timeout
from typing import Coroutine
class Request:
# Default config
REQUEST_CONFIG = {
‘RETRIES‘: 3,
‘DELAY‘: 0,
‘TIMEOUT‘: 10,
‘RETRY_FUNC‘: Coroutine,
‘VALID‘: Coroutine
}
METHOD = [‘GET‘, ‘POST‘]
def __init__(self, url, method=‘GET‘, request_config=None, request_session=None):
self.url = url
self.method = method.upper()
self.request_config = request_config or self.REQUEST_CONFIG
self.request_session = request_session
@property
def current_request_session(self):
if self.request_session is None:
self.request_session = aiohttp.ClientSession()
self.close_request_session = True
return self.request_session
async def fetch(self):
"""Fetch all the information by using aiohttp"""
if self.request_config.get(‘DELAY‘, 0) > 0:
await asyncio.sleep(self.request_config[‘DELAY‘])
timeout = self.request_config.get(‘TIMEOUT‘, 10)
async with async_timeout.timeout(timeout):
resp = await self._make_request()
try:
resp_data = await resp.text()
except UnicodeDecodeError:
resp_data = await resp.read()
resp_dict = dict(
rl=self.url,
method=self.method,
encoding=resp.get_encoding(),
html=resp_data,
cookies=resp.cookies,
headers=resp.headers,
status=resp.status,
history=resp.history
)
await self.request_session.close()
return type(‘Response‘, (), resp_dict)
async def _make_request(self):
if self.method == ‘GET‘:
request_func = self.current_request_session.get(self.url)
else:
request_func = self.current_request_session.post(self.url)
resp = await request_func
return resp
if __name__ == ‘__main__‘:
loop = asyncio.get_event_loop()
resp = loop.run_until_complete(Request(‘https://docs.python-ruia.org/‘).fetch())
print(resp.status)
200,就这样简单封装一下,我们已经有了自己的请求类Request,接下来只需要再完善一下重试机制以及将返回的属性封装一下就基本完成了:# 重试函数
async def _retry(self):
if self.retry_times > 0:
retry_times = self.request_config.get(‘RETRIES‘, 3) - self.retry_times + 1
self.retry_times -= 1
retry_func = self.request_config.get(‘RETRY_FUNC‘)
if retry_func and iscoroutinefunction(retry_func):
request_ins = await retry_func(weakref.proxy(self))
if isinstance(request_ins, Request):
return await request_ins.fetch()
return await self.fetch()
ruia/request.py即可,接下来就可以利用Request来实际请求一个目标网页,如下: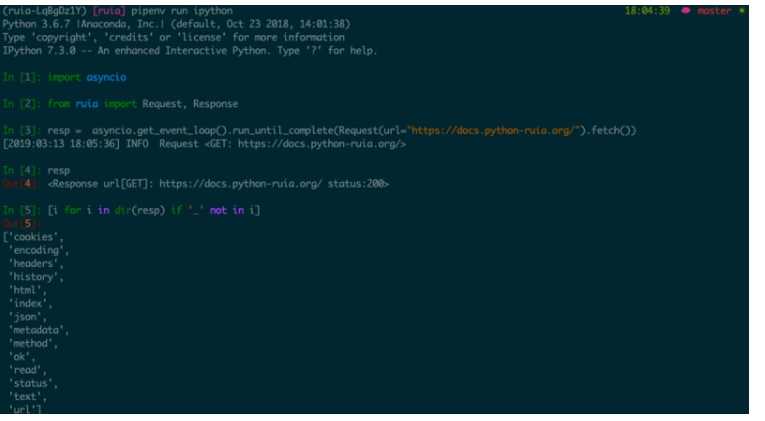
https://docs.python-ruia.org/并返回了Response对象,其中Response提供属性介绍如下:
Field & Item
ORM的思想很适合用在这里,我们只需要定义一个Item类,类里面每个属性都可以用Field类来定义,然后只需要传入url或者html,执行过后Item类里面 定义的属性会自动被提取出来变成目标字段值HackerNews网页的title和url,可以这样实现:import asyncio
from ruia import AttrField, TextField, Item
class HackerNewsItem(Item):
target_item = TextField(css_select=‘tr.athing‘)
title = TextField(css_select=‘a.storylink‘)
url = AttrField(css_select=‘a.storylink‘, attr=‘href‘)
async def main():
async for item in HackerNewsItem.get_items(url="https://news.ycombinator.com/"):
print(item.title, item.url)
if __name__ == ‘__main__‘:
items = asyncio.run(main())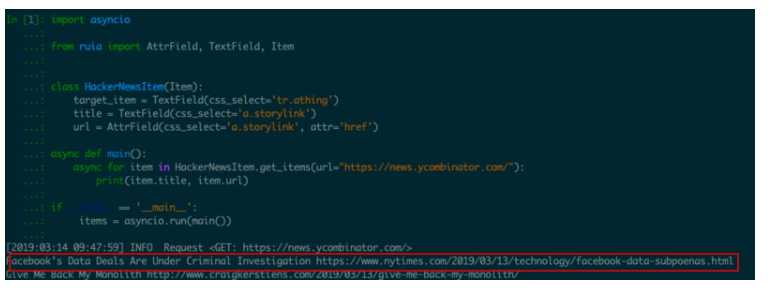
title和url属性已经被赋与实际的目标值,这样写起来是不是很简洁清晰也很明了呢?Field类的目的是提供多种方式让开发者提取网页字段,比如:
class BaseField(object):
"""
BaseField class
"""
def __init__(self, default: str = ‘‘, many: bool = False):
"""
Init BaseField class
url: http://lxml.de/index.html
:param default: default value
:param many: if there are many fields in one page
"""
self.default = default
self.many = many
def extract(self, *args, **kwargs):
raise NotImplementedError(‘extract is not implemented.‘)
class _LxmlElementField(BaseField):
pass
class AttrField(_LxmlElementField):
"""
This field is used to get attribute.
"""
pass
class HtmlField(_LxmlElementField):
"""
This field is used to get raw html data.
"""
pass
class TextField(_LxmlElementField):
"""
This field is used to get text.
"""
pass
class RegexField(BaseField):
"""
This field is used to get raw html code by regular expression.
RegexField uses standard library `re` inner, that is to say it has a better performance than _LxmlElementField.
"""
pass
ruia/field.pyItem部分,这部分实际上是对ORM那块的实现,用到的知识点是元类,因为我们需要控制类的创建行为:class ItemMeta(type):
"""
Metaclass for an item
"""
def __new__(cls, name, bases, attrs):
__fields = dict({(field_name, attrs.pop(field_name))
for field_name, object in list(attrs.items())
if isinstance(object, BaseField)})
attrs[‘__fields‘] = __fields
new_class = type.__new__(cls, name, bases, attrs)
return new_class
class Item(metaclass=ItemMeta):
"""
Item class for each item
"""
def __init__(self):
self.ignore_item = False
self.results = {}
Item类只需要定义两个方法就能实现:
target_item
ruia/item.pySpider
Ruia框架中,为什么要有Spider,有以下原因:
Spider可以对这些进行 有效的管理Ruia框架的API写法我有参考Scrapy,各个函数之间的联结也是使用回调,但是你也可以直接使用await,可以直接看代码示例:from ruia import AttrField, TextField, Item, Spider
class HackerNewsItem(Item):
target_item = TextField(css_select=‘tr.athing‘)
title = TextField(css_select=‘a.storylink‘)
url = AttrField(css_select=‘a.storylink‘, attr=‘href‘)
class HackerNewsSpider(Spider):
start_urls = [f‘https://news.ycombinator.com/news?p={index}‘ for index in range(1, 3)]
async def parse(self, response):
async for item in HackerNewsItem.get_items(html=response.html):
yield item
if __name__ == ‘__main__‘:
HackerNewsSpider.start()[2019:03:14 10:29:04] INFO Spider Spider started!
[2019:03:14 10:29:04] INFO Spider Worker started: 4380434912
[2019:03:14 10:29:04] INFO Spider Worker started: 4380435048
[2019:03:14 10:29:04] INFO Request Spider的核心部分在于对请求URL的请求控制,目前采用的是生产消费者模式来处理,具体函数如下: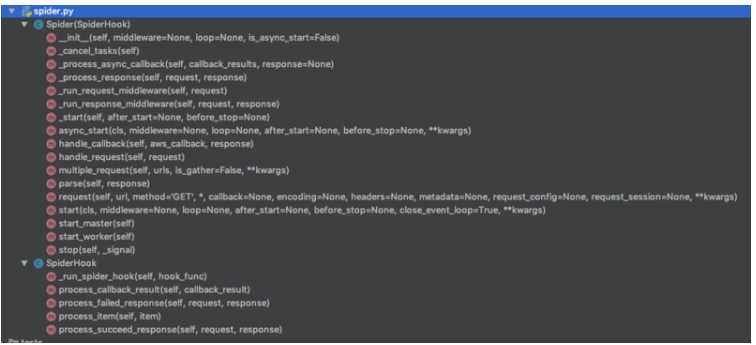
ruia/spider.py更多