【NLP-06】fastText文本分类算法
2021-05-12 02:29
标签:pat ict sele 我爱你 子节点 mamicode 表达 targe embedding 目录
一句话简述:fastText提出了子词嵌入(subword embedding)的方法。是一种监督学习方法。和word2vec 中的CBOW结构很相似。运行速度较快。
? 一、fastText概述
1.1 背景
在word2vec中,我们并没有直接利用构词学中的信息。无论是在跳字模型还是连续词袋模型中,我们都将形态不同的单词用不同的向量来表示。例如,"dog"和"dogs"分别用两个不同的向量表示,而模型中并未直接表达这两个向量之间的关系。 这里有一点需要特别注意,一般情况下,使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物。除非你决定使用预训练的embedding来训练fastText分类模型,这另当别论。
1.2 n-gram表示单词
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:"book" 和"books","阿里巴巴"和"阿里",这两个例子中,两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词"book",假设n的取值为3,则它的trigram有:" 这带来两点好处:
1.3 什么是FastText
FastText 文本分类算法是由Facebook AI Research 提出的一种简单的模型。实验表明一般情况下,FastText 算法能获得和深度模型相同的精度,但是计算时间却要远远小于深度学习模型。fastText 可以作为一个文本分类的 baseline 模型。
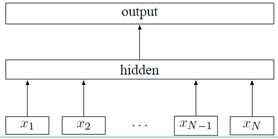
二、模型架构
fastText 的模型架构和 word2vec 中的CBOW结构很相似,具体的模型结构如下:
上面图中?xi?表示的是文本中第?i?个词的特征向量,该模型的负对数似然函数如下:
式子中的 B 是函数?f?的权重系数,上面式子中的矩阵 A 是词查找表,整个模型是查找出所有的词表示之后取平均值,用该平均值来代表文本表示,然后将这个文本表示输入到线性分类器中,也就是输出层的 softmax 函数。
三、分层 softmax(Hierarchical softmax)
首先来看看softmax 函数的表达式如下:
然而在类别非常多的时候,利用softmax 计算的代价是非常大的,时间复杂度为?O(kh) ,其中?k?是类别的数量,h?是文本表示的维度。而基于霍夫曼树否建的层次 softmax 的时间复杂度为?O(h*log2(k))?(二叉树的时间复杂度是?O(log2(k))?)。霍夫曼树是从根节点开始寻找,而且在霍夫曼树中权重越大的节点越靠近根节点,这也进一步加快了搜索的速度。
四、关于效果和应用
4.1 N-grams 特征
传统的词袋模型不能保存上下文的语义,例如"我爱你"和"你爱我"在传统的词袋模型中表达的意思是一样的,N-grams 模型能很好的保存上下文的语义,能将上面两个短语给区分开。而且在这里使用了 hash trick 进行特征向量降维。hash trick 的降维思想是讲原始特征空间通过 hash 函数映射到低维空间。
4.2 效果比较
还有个问题,就是为何fastText的分类效果常常不输于传统的非线性分类器?假设我们有两段文本:
1、我 来到 达观数据
2、俺 去了 达而观信息科技
这两段文本意思几乎一模一样,如果要分类,肯定要分到同一个类中去。但在传统的分类器中,用来表征这两段文本的向量可能差距非常大。传统的文本分类中,你需要计算出每个词的权重,比如tf-idf值, "我"和"俺" 算出的tf-idf值相差可能会比较大,其它词类似,于是,VSM(向量空间模型)中用来表征这两段文本的文本向量差别可能比较大。
但是fastText就不一样了,它是用单词的embedding叠加获得的文档向量,词向量的重要特点就是向量的距离可以用来衡量单词间的语义相似程度,于是,在fastText模型中,这两段文本的向量应该是非常相似的,于是,它们很大概率会被分到同一个类中。使用词embedding而非词本身作为特征,这是fastText效果好的一个原因;另一个原因就是字符级n-gram特征的引入对分类效果会有一些提升 。
4.3 应用
fastText作为诞生不久的词向量训练、文本分类工具得到了比较深入的应用。主要被用在以下两个系统:
1. 同近义词挖掘。Facebook开源的fastText工具也实现了词向量的训练,基于各种垂直领域的语料,使用其挖掘出一批同近义词;
2. 文本分类系统。在类标数、数据量都比较大时,选择fastText 来做文本分类,以实现快速训练预测、节省内存的目的。
五、fastText与Word2Vec的不同
有意思的是,fastText和Word2Vec的作者是同一个人。
相同点:
之前一直不明白fasttext用层次softmax时叶子节点是啥,CBOW很清楚,它的叶子节点是词和词频,看源码可知,其实fasttext叶子节点里是类标和类标的频数。
?? Word2Vec fastText 输入 one-hot形式的单词的向量 embedding过的单词的词向量和n-gram向量 输出 对应的是每一个term,计算某term概率最大 对应的是分类的标签 类型 无监督学习 有监督学习 本质不同,体现在softmax的使用:
word2vec的目的是得到词向量,该词向量最终是在输入层得到的,输出层对应的h-softmax也会生成一系列的向量,但是最终都被抛弃,不会使用。
fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label
fastText优点:
六、代码实现
import jieba "" # 预测文档类别 # 预测类别+概率 # 得到前k个类别 # 得到前k个类别+概率 参考文献
【1】英文的论文: Bag of Tricks for Efficient Text Classification
【2】其他人的理解: http://www.52nlp.cn/fasttext
【3】代码: https://github.com/NLP-LOVE/ML-NLP/blob/master/NLP/16.2%20fastText/fastText.ipynb
【NLP-06】fastText文本分类算法 标签:pat ict sele 我爱你 子节点 mamicode 表达 targe embedding 原文地址:https://www.cnblogs.com/yifanrensheng/p/13143991.html
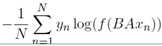
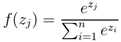
import fasttext as ft
from skllearn.model_selection import train_test_split
分词
去停用词
把处理过后的词写入文本
""
# 有监督的学习,训练分类器
classifier = ft.supervised(filePath, "classifier.model")
result = classifier.test(filePath)
labels = classifier.predict(texts)
labelProb = classifier.predict_proba(texts)
labels = classifier.predict(texts, k=3)
labelProb = classifier.predict_prob(texts, k=3)
文章标题:【NLP-06】fastText文本分类算法
文章链接:http://soscw.com/index.php/essay/84496.html