How JavaScript works in browser and node?
2021-05-12 11:30
There are many passionate developers, working on front-end or back-end, devote their life to protect realm of JavaScript. JavaScript is very easy to understand and is a essential part of front-end development. But unlike other programming languages, it’s single threaded. That means, code execution will be done one at a time. Since code execution is done sequentially, any code that takes longer time to execute, will block anything that needs to be executed. Hence sometimes you see below screen while using Google Chrome.
When you open a website in browser, it uses a single JavaScript execution thread. That thread is responsible to handle everything, like scrolling the web page, printing something on the web page, listen to DOM events (like when user clicks a button) and doing other things. But when JavaScript execution is blocked, browser will stop doing all those things, which means browser will simply freeze and won’t respond to anything.
You can see that in action using below eternal while loop.
while(true){}
Any code after above statement won’t be executed as while loop will loop infinitely until system is out of resources. This can also happen in infinitely recursive function call.
Thanks to modern browsers, as not all open browser tabs rely on single JavaScript thread. Instead they use separate JavaScript thread per tab or per domain. In case of Google Chrome, you can open multiple tabs with different websites and run above eternal while loop. That will only freeze current tab where that code was executed but other tabs will function normally. Any tab having page opened from same domain / same website will also freeze as Chrome implements one-process-per-site policy and a process uses same JavaScript execution thread.
To visualize, how JavaScript executes a program, we need to understand JavaScript runtime.

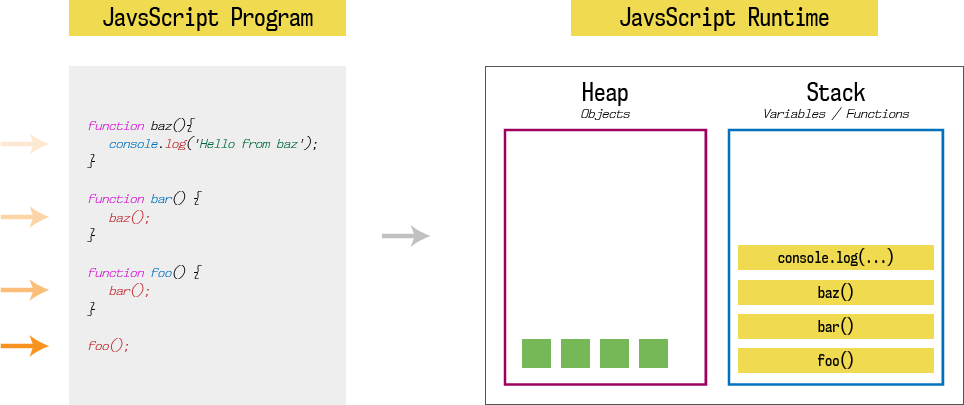
Like any other programming language, JavaScript runtime has one stack and one heap storage. I am not going to explain much more about heap, you can read it here. What we are interested in is stack. Stack is LIFO (last in, first out) data storage which store current function execution context of a program. When our program is loaded into the memory, it starts execution from the first function call which is foo().
Hence, first stack entry is foo(). Since foo function calls bar function, second stack entry is bar(). Since bar function calls baz function, third stack entry is baz(). And finally, baz function calls console.log, fourth stack entry is console.log(‘Hello from baz‘).
Until a function returns something (while function is executing), it won’t be popped out from the stack. Stack will pop entries one by one as soon as that entry (function) returns some value, and it will continue pending function executions.

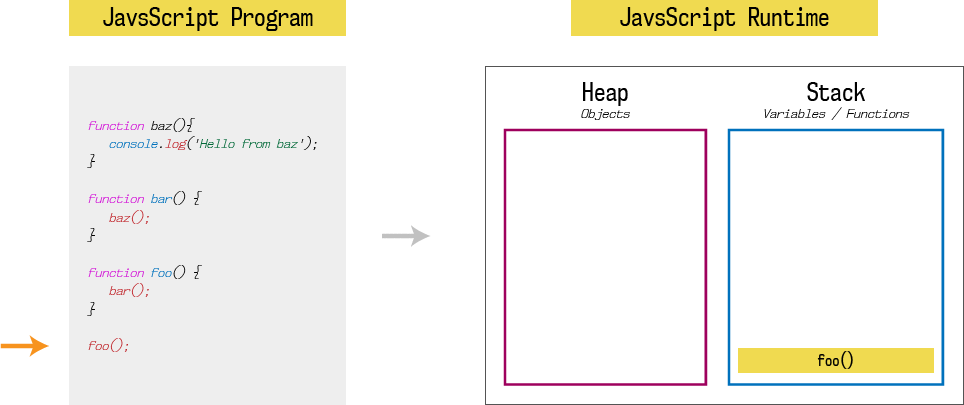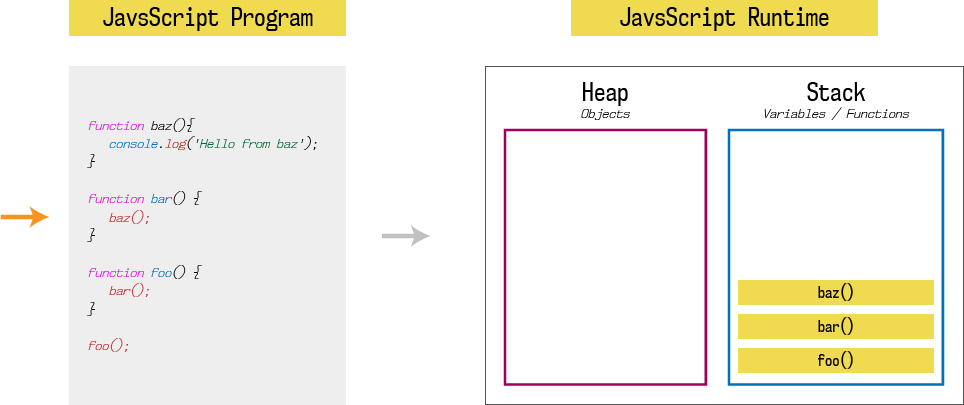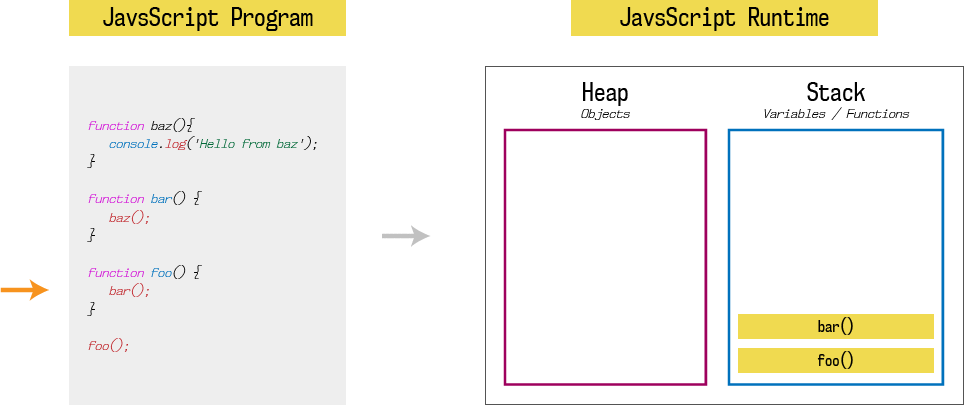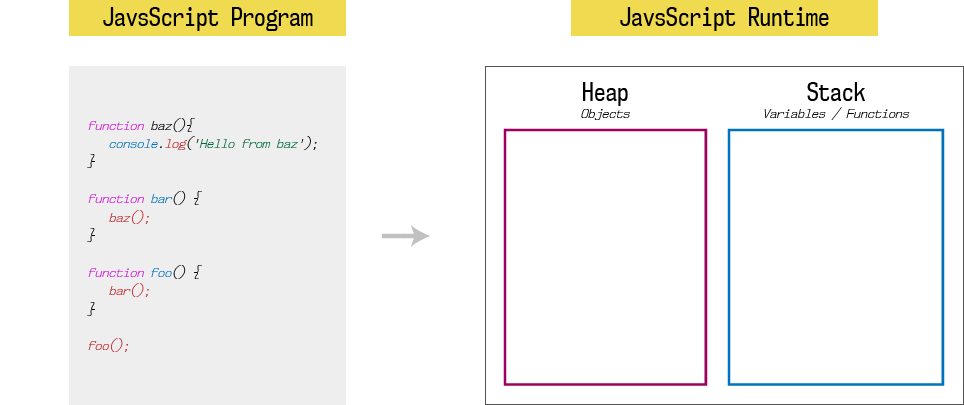
At each entry, state of the stack also called as stack frame. If any function call at given stack frame produces an error, JavaScript will print stack trace which is nothing but a snapshot of code execution at that stack frame.
function baz(){
throw new Error(‘Something went wrong.‘);
}function bar() {
baz();
}function foo() {
bar();
}foo();
In above program, we threw error from baz function and JavaScript will print below stack trace to figure out what went wrong and where.


Since JavaScript is single threaded, it has only one stack and one heap. Hence, if any other program want to execute something, it has to wait until previous program is completely executed.
This is bad for any programming language but JavaScript was designed to be used as general purpose programming language, not for very complex stuff.
So let’s think of one scenario. What if a browser sends a HTTP request to load some data over network or to load an image to display on web page. Will browser freeze until that request is resolved? If it does, then it’s very bad for user experience.
Browser comes with a JavaScript engine which provides JavaScript runtime environment. For example, Google chrome uses V8 JavaScript engine, developed by them. But guess what, browser uses more than just a JavaScript engine. This is what browser under the hood looks like.
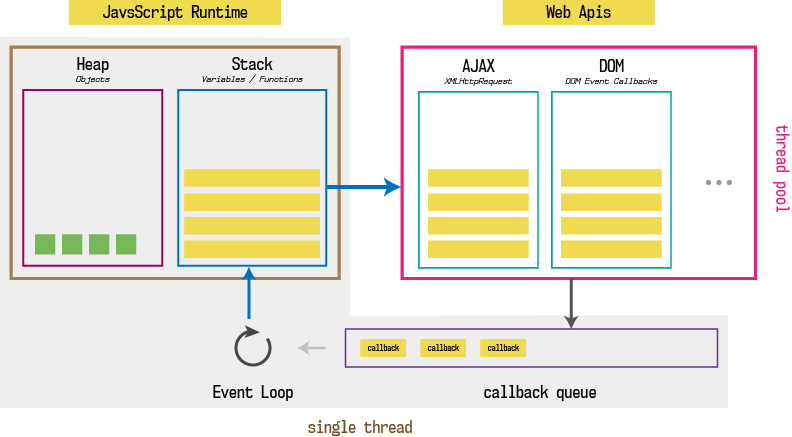
Looks really complex but it is very easy to understand. JavaScript runtime actually consist of 2 more components viz. event loop and callback queue. Callback queue is also called as message queue or task queue.
Apart from JavaScript engine, browser contains different applications which can do variety of things like send HTTP requests, listen to DOM events, delay execution using setTimeout or setInterval, caching, database storage and much more. These features of browser help us create rich web applications.
But think about this, if browser had to use same JavaScript thread for execution of these feature, then user experience would have been horrible. Because even when user is just scrolling the web page, there are many things going on, in the background. Hence, browser uses low level language like C++ to perform these operations and provide clean JavaScript API to work with. These APIs are known as Web APIs.
These Web APIs are asynchronous. That means, you can instruct these APIs to do something in background and return data once done, meanwhile we can continue further execution of JavaScript code. While instructing these APIs to do something in background, we have to provide a callback function. Responsibility of callback function is to execute some JavaScript once Web API is done with it’s work. Let’s understand how all pieces work together.
So when you call a function, it gets pushed to the stack. If that function contains Web API call, JavaScript will delegate control of it to the Web API with a callback function and move to the next lines until function returns something. Once function hits return statement, that function is popped from the stack and move to the next stack entry. Meanwhile, Web API is doing it’s job in the background and remembers what callback function is associated with that job. Once job is done, Web API binds result of that job to callback function and publishes a message to message queue (AKA callback queue) with that callback. The only job of event loop is to look at callback queue and once there is something pending in callback queue, push that callback to the stack. Event loop pushes one callback function at a time, to the stack, once the stack is empty. Later, stack will execute callback function.
Let’s see how everything works step by step using setTimeout Web API. setTimeout Web API is mainly used to execute something after few seconds. This execution happens once all code in the program is done executing (when stack is empty). The syntax for setTimeout function is as below.
setTimeout(callbackFunction, timeInMilliseconds);
callbackFunction is a callback function which will execute after timeInMilliseconds. Let’s modify our earlier program and use this API.
function printHello() {
console.log(‘Hello from baz‘);
}function baz() {
setTimeout(printHello, 3000);
}function bar() {
baz();
}function foo() {
bar();
}foo();
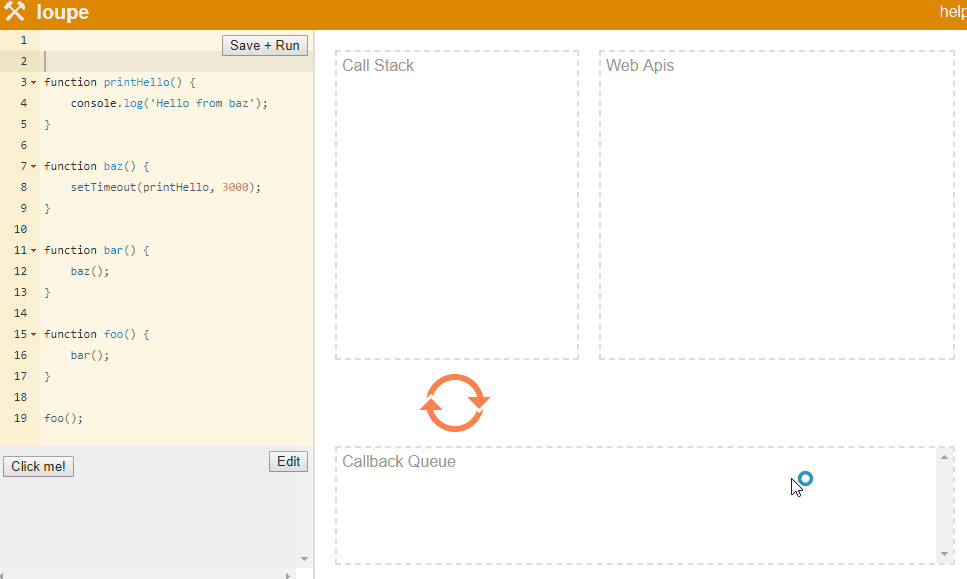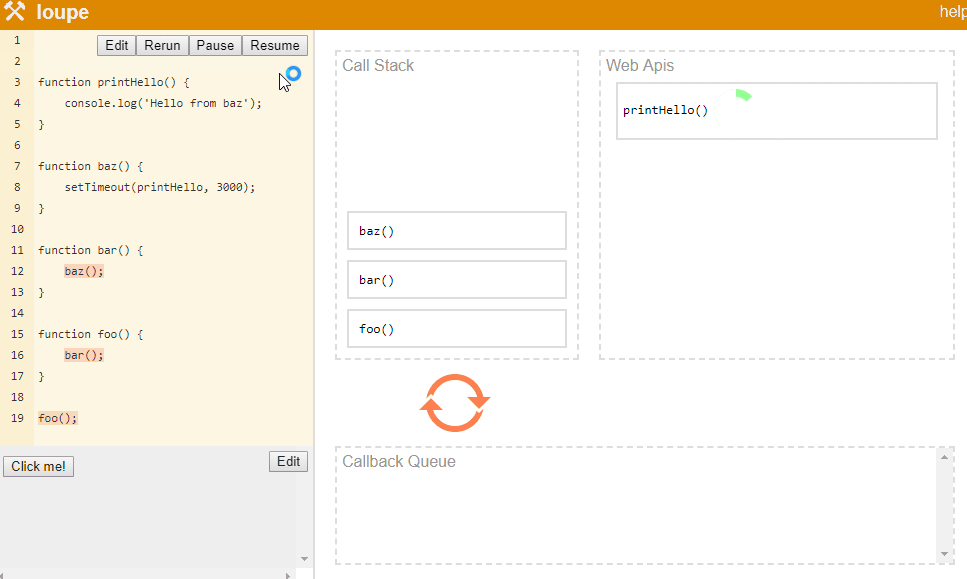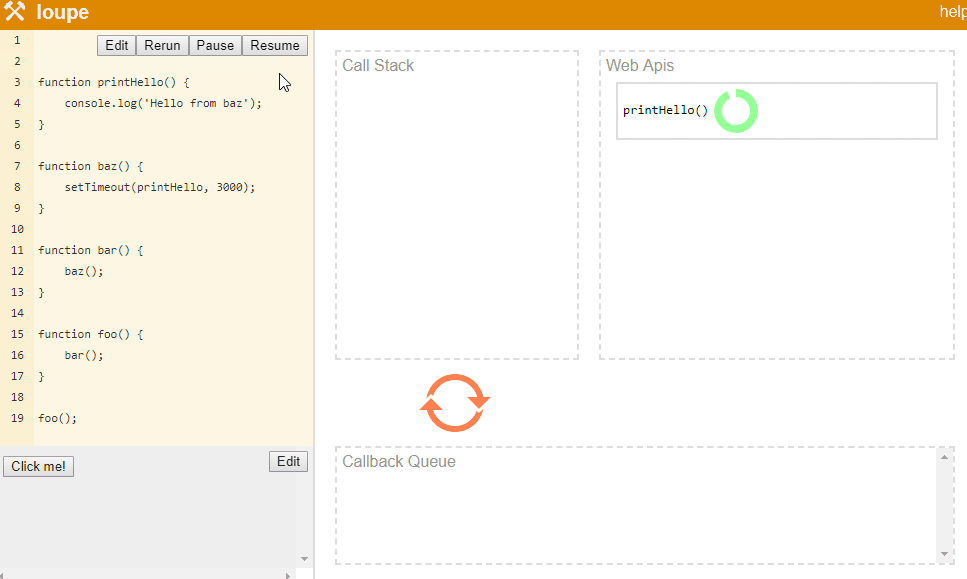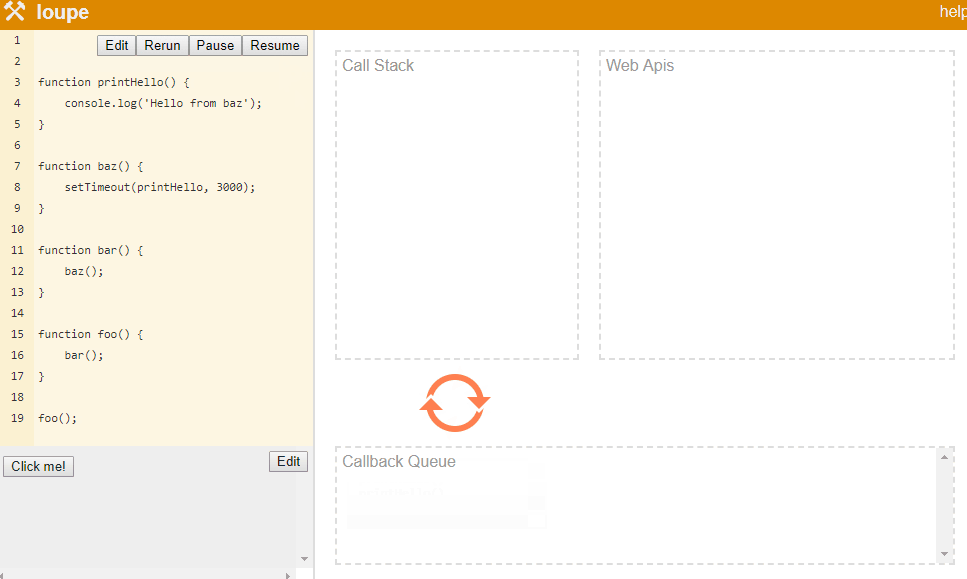
The only modification done to the program is, we delayed console.log execution by 3 seconds. In this case, stack will keep building up like foo() => bar() => baz(). Once baz starts executing and hits setTimeout API call, JavaScript will pass callback function to the Web API and move to the next line. Since, there is no next line, stack will pop baz, then bar and then foo function calls. Meanwhile, Web API is waiting for 3 seconds to pass. Once 3 seconds are passed, it will push this callback to callback queue and since stack is empty, event loop will put this callback back on the stack where execution of this callback will happen.
Philip Robers has created a amazing online tool to visualize how JavaScript works underneath. Our above example is available at this link.

文章标题:How JavaScript works in browser and node?
文章链接:http://soscw.com/index.php/essay/84673.html