Python数据挖掘—分类—随机森林
2021-05-17 18:30
标签:森林 val 情况下 png nbsp bsp data 实现 res 决策树评分: 随机森林评分: 发现随机森林在不调优的情况下,得分高于决策树模型 决策树评分: 随机森林评分: Python数据挖掘—分类—随机森林 标签:森林 val 情况下 png nbsp bsp data 实现 res 原文地址:https://www.cnblogs.com/U940634/p/9746336.html
概念
随机森林(RandomForest):随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别数输出的类别的众数而定
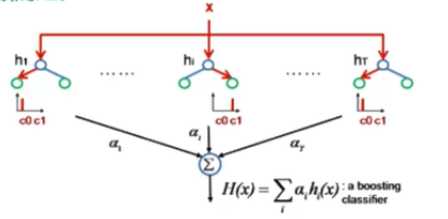
优点:适合离散型和连续型的属性数据;对海量数据,尽量避免了过度拟合的问题;对高维数据,不会出现特征选择困难的问题;实现简单,训练速度快,适合 进行分布式计算


1 import pandas;
2
3 data = pandas.read_csv(
4 "D:\\PDM\\5.3\\data.csv"
5 );
6
7 dummyColumns = ["Gender", "ParentEncouragement"]
8
9 for column in dummyColumns:
10 data[column]=data[column].astype(‘category‘)
11
12 dummiesData = pandas.get_dummies(
13 data,
14 columns=dummyColumns,
15 prefix=dummyColumns,
16 prefix_sep="=",
17 drop_first=True
18 )
19 dummiesData.columns
20
21 fData = dummiesData[[
22 ‘ParentIncome‘, ‘IQ‘, ‘Gender=Male‘,
23 ‘ParentEncouragement=Not Encouraged‘
24 ]]
25
26 tData = dummiesData["CollegePlans"]
27
28 from sklearn.tree import DecisionTreeClassifier
29 from sklearn.ensemble import RandomForestClassifier
30 from sklearn.model_selection import cross_val_score
31
32 dtModel = DecisionTreeClassifier()
33
34 dtScores = cross_val_score(
35 dtModel,
36 fData, tData, cv=10
37 )
38
39 dtScores.mean()
40
41 rfcModel = RandomForestClassifier()
42
43 rfcScores = cross_val_score(
44 rfcModel,
45 fData, tData, cv=10
46 )
47
48 rfcScores.mean()
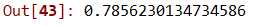
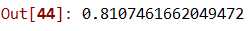
调优:设置:max_leaf_nodes=8
1 #对连个模型进行调优
2 dtModel=DecisionTreeClassifier(max_leaf_nodes=8)
3
4 dtScores=cross_val_score(
5 dtModel,
6 fData,tData,cv=10)
7
8 dtScores.mean()
9
10 rfcModel=RandomForestClassifier(max_leaf_nodes=8)
11
12 rfcScores=cross_val_score(
13 rfcModel,
14 fData,tData,cv=10)
15
16 rfcScores.mean()
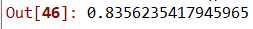
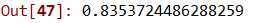
文章标题:Python数据挖掘—分类—随机森林
文章链接:http://soscw.com/index.php/essay/86835.html