cnn经典网络-MobileNet V1 V2
2021-05-29 08:00
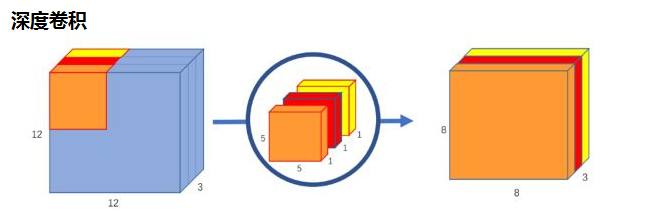
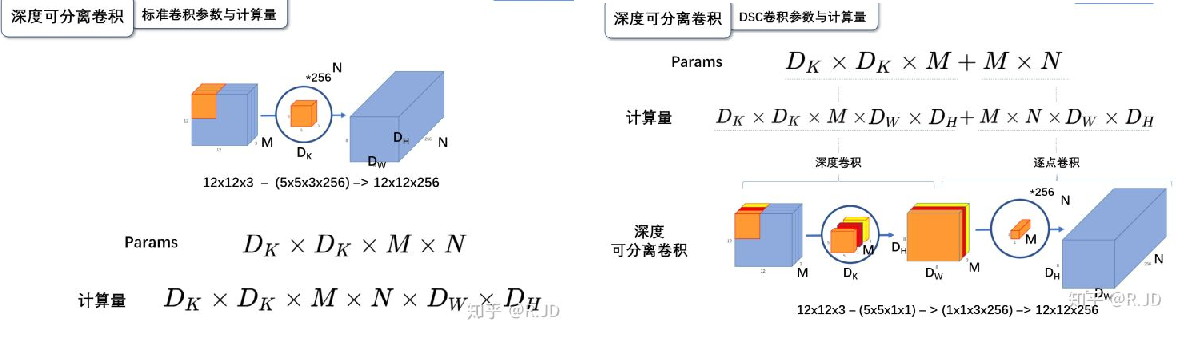
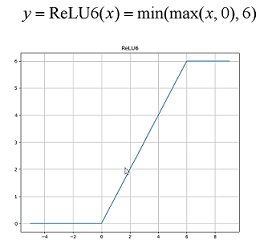
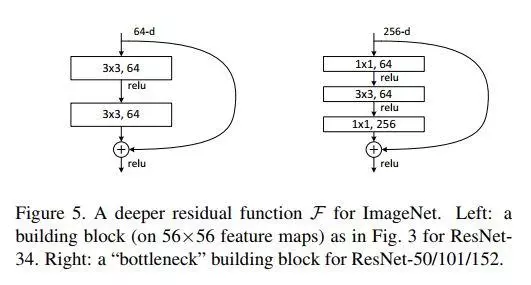
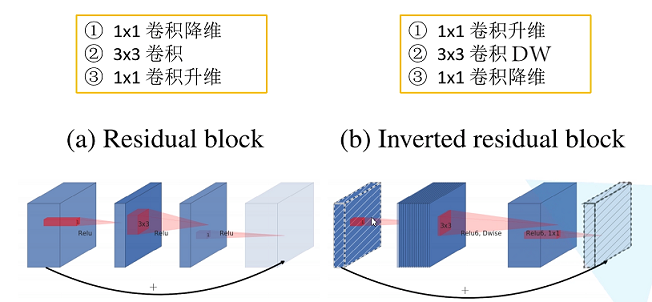
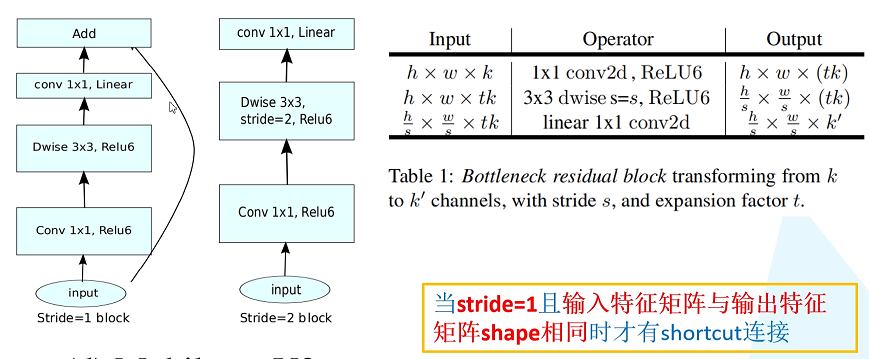
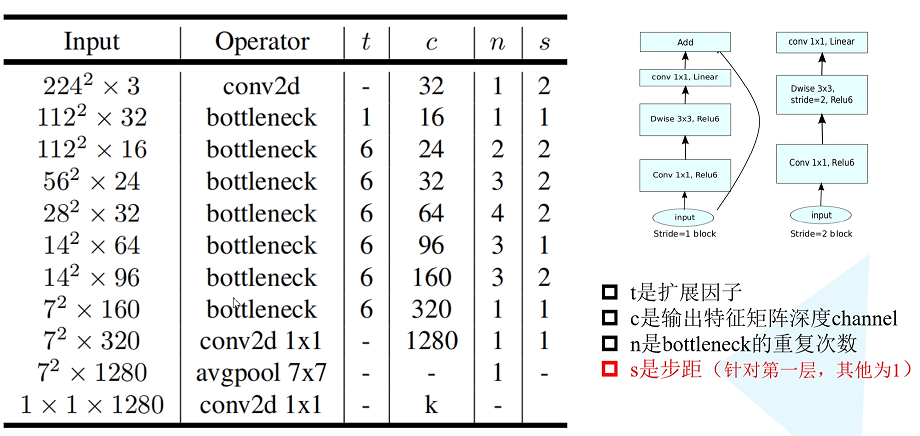
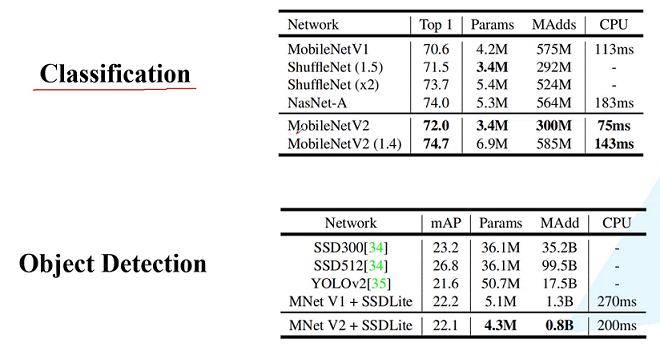
标签:部分 idt 总结 cnn 效果 研究 做了 inf 轻量 paper https://arxiv.org/abs/1704.04861 MobileNet 由谷歌在 2017 年提出,是一款专注于在移动设备和嵌入式设备上的 轻量级 CNN神经网络,并 迅速 衍生了 v1 v2 v3 三个版本; 相比于传统的 CNN 网络,在准确率小幅降低的前提下,大大减小模型参数和运算量; 一句话概括,V1 就是 把 vgg 中标准卷积层 换成了 深度可分离卷积; 模型亮点: 1. 深度可分离卷积,大大减少参数量 2. 增加超参 α、β 可分离卷积大致可以分为 空间可分离 和 深度可分离; 顾名思义,就是把一个 大卷积核 换成两个 小卷积核,例如; 非本文重点,简单介绍; 深度可分离 由 深度卷积 + 逐点卷积 组成; 深度卷积:论文中称为 DW 卷积,就是 把 卷积核 变成 单通道,输入有 M 个通道数,就需要 M 个卷积核,每个通道 分别进行卷积,最后做叠加,如下图 逐点卷积:论文中称为 PW 卷积,就是用 1x1 的卷积核进行卷积,作用是 对深度卷积后的 特征 进行 升维; 上面两步实现的效果如下图 可以看到输出 的 shape 是一样的; 下面我们看看在 输入输出 shape 一样时各自的参数量 标准卷积 params:Dk x Dk x M x N 计算量:Dk x Dk x M x Dh x Dw x N 可分离卷积 params:Dk x Dk x M + M x N 计算量:Dk x Dk x M x Dh x Dw + M x Dh x Dw x N 计算一下减少量 N 为 输出通道数, Dk 为 卷积核 size,如果 size 为 3,减小了 1/9 左右,厉害了; 把 vgg 的标准卷积 和 V1 的深度可分离卷积 对比看下 看到了 深度卷积 (3x3 Depthwise)和逐点卷积 (1x1 conv); 同时看到了 Relu6,什么鬼? 上图,一看便知 Relu6 对 大于 0 的部分做了一个边界,作者认为,在模型精度要求不是很高的情况下,边界使得模型鲁棒性更强; 强行压缩数值比较大的特征,避免了 个性特征,也相当于 规范了特征,防止过拟合,玄学要自己体会; 说了那么多,该上结果了 Conv 代表标准卷积,Conv dw 代表深度可分离卷积,s2 代表步长为2,s1 代表步长为1; 标准卷积是在 原特征 上进行多次卷积,而 深度可分离卷积 是在 卷积后的 特征上 进行 多次卷积,直观的感觉是,后者提取的特征不如前者,性能应该差点; 为了验证 V1 的效果,作者做了各种实验; 1. 分别用 标准卷积 和 深度可分离卷积 实现 MobileNetV1 可以看到 效果确实不如 标准卷积,但是 ACC 相差不大, 可喜的是 参数量和计算量 大大降低,约 1/9; 2. 把 V1 和 其他经典网络比较 ACC 优于 GoogleNet,差于 VGG16,但相差都不太大,但是参数量和计算量大大降低; 3. 把 V1 用于 目标检测算法 mAP 相差不是特别大,计算量大大降低; 总结一句话,就是 V1 效果不输其他网络,但计算量和参数量大大降低; 使用中发现, depthwise 部分的卷积核很容易废掉,即卷积核参数大部分为 0; MobileNetV2 对此进行了分析和优化; paper https://arxiv.org/abs/1801.04381 MobileNetV2 是由 谷歌 在 2018 年提出,相比 V1,准确率更好,模型更小; 模型亮点: 1. Inverted Residuals(倒残差结构) 2. Linear bottlenecks 一看到 残差,就想到 resnet 了,先来看看 resnet 的 residual block 我们看右边的 block,在 resnet 中 这个 block 专为 深层网络设计,可大大减少 参数量;它先 通过 1x1 把 256 channel 变成 64 做降维,然后是 3x3 conv,再接着 1x1 还原为 256 channel 做升维; 总结一句就是先降维再升维,两头胖,中间瘦; 而 倒残差结构就是 两头瘦,中间胖; 如下图 在具体网络设计时,经过试验,作者并不是把 所有 block 都加上了 残差结构,所以 V2 中有两种 block; 只有 Stride=1 时,才有 残差结构; 我们看到上面的 残差结构 末尾 是 Linear 而不是 Relu,为什么呢? 作者经过研究,发现在 V1 中 depthwise 中有 0 卷积的原因就是 Relu 造成的,换成 Linear 解决了这个问题; 作者做了如下实验 作者把一个 二维 流形 数据【图1】 作为 输入, 然后 用不同维度的矩阵 T 把它映射到 高维,然后经过 Relu 输出,再把 输出 经过 T-1 还原成 二维,发现,在 低维 【图2 3】 时,Relu 对信号的损失非常大,随着维度增加,损失越来越小; 结论就是 Relu 对低维信号 损失很大; 回想一下 深度卷积,深度卷积是单通道卷积,只有 1 维,经过 relu 后,即使是 融合后再 Relu 也只有 3 维,信号损失很大,如果学到的信号完全没有用,那就不用学了, w 自然是 0 ; 问题又来了,既然 depthwise 时 relue 造成了信号损失,为什么不换 DW 的 relue,而是把 逐点卷积 的 激活函数 换成 Linear 了? 1. 首先 dw 的 relu 造成 大量损失是因为 Input 的 channel 太少了,如果 Input 的 channel 不少呢,就不损失了,那就没问题了,所以重点不是换不换 relue,是解决 低 channel 的问题; 2. 既然 channel 少,我给你增加 channel 不就好了,就是 1x1 升维咯; 3. 升完了,我再降回来,将回来之后, channel 就少了,那就换成 linear 咯; 4. 于是 倒残差结构 形成咯,再就是画道线的事,参考 resnet 而已; 一句话,又好又快 cnn经典网络-MobileNet V1 V2 标签:部分 idt 总结 cnn 效果 研究 做了 inf 轻量 原文地址:https://www.cnblogs.com/guweixin/p/14752249.html转自 https://www.cnblogs.com/yanshw/p/12563872.html
MobileNetV1
可分离卷积
空间可分离
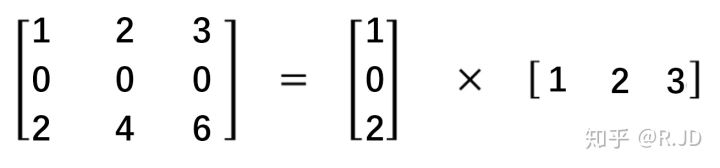
深度可分离
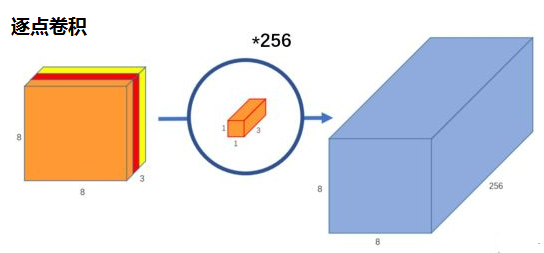
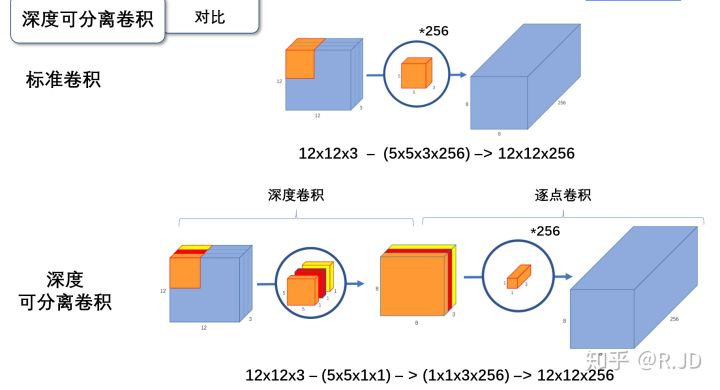
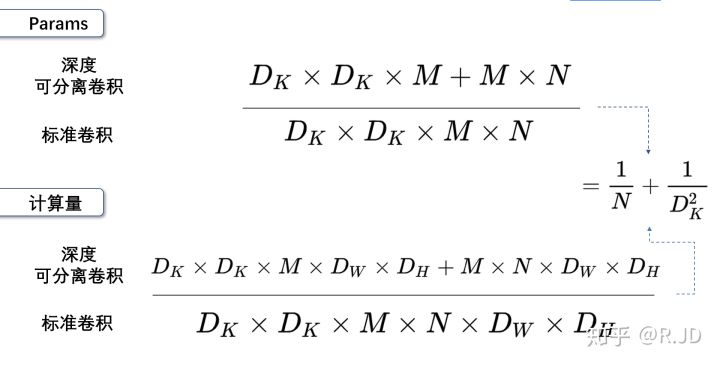
V1 卷积结构
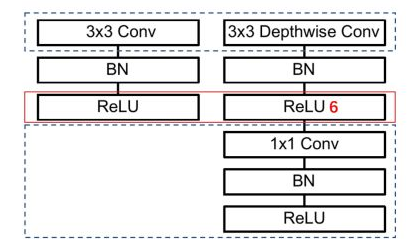
Relu6
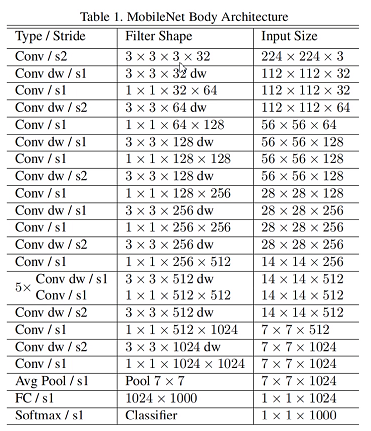
V1 网络结构
V1 模型效果


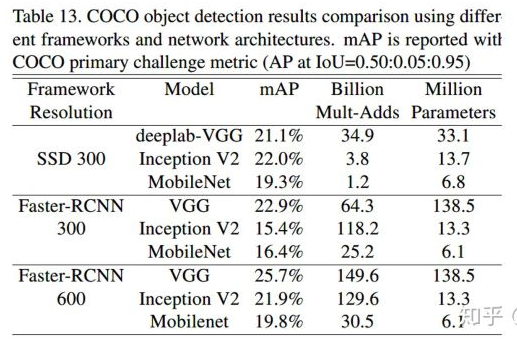
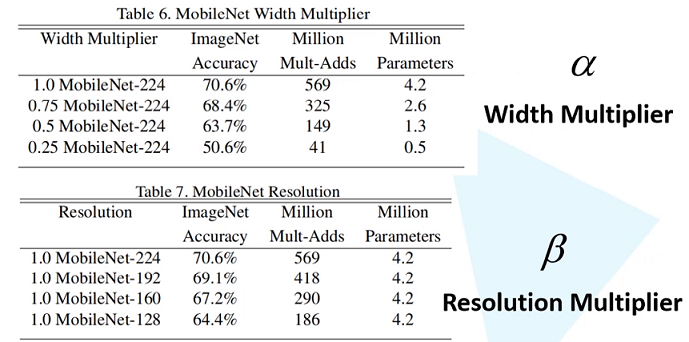
超参数对比
缺点
MobileNetV2
倒残差结构
Linear bottlenecks
Relu 为什么被换掉

V2 网络结构
V2 模型效果
下一篇:css悬停效果
文章标题:cnn经典网络-MobileNet V1 V2
文章链接:http://soscw.com/index.php/essay/89016.html