爬虫-css选择器(7)
2021-01-20 00:13
阅读:682
YPE html>
标签:mooc info 高级 doctype pytho code scrapy import 代码
基本语法:
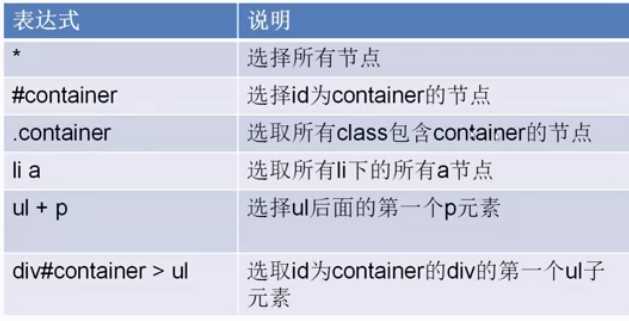
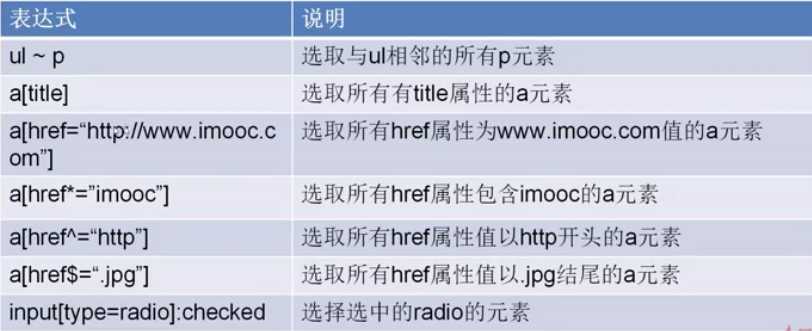

代码实现:
html = """bobby基本信息 """ from scrapy import Selector sel = Selector(text=html) teacher_info_tag = sel.css(".teacher_info") info_tag = sel.css("#info") age_css = ".teacher_info p:nth_child(2)::text" age = sel.css(age_css).extract()[0] course_url = sel.css("a[href*=‘imooc‘]::text").extract() sibling_p = sel.css("p.name ~ p::text").extract() print(age) #bs的接口提取方式 #xpath提取 #css提取讲师信息
python全栈工程师,7年工作经验,喜欢钻研python技术,对爬虫、 web开发以及机器学习有浓厚的兴趣,关注前沿技术以及发展趋势。年龄: 29
姓名: bobby
工作年限: 7年
职位: python开发工程师
课程信息
课程名 讲师 地址 django打造在线教育 bobby 访问 python高级编程 bobby 高级编程访问 scrapy分布式爬虫 bobby 访问 django rest framework打造生鲜电商 bobby 访问 tornado从入门到精通 bobby 访问
爬虫-css选择器(7)
标签:mooc info 高级 doctype pytho code scrapy import 代码
原文地址:https://www.cnblogs.com/topass123/p/13330126.html
上一篇:css基础篇13--浮动属性
评论
亲,登录后才可以留言!