卡耐基梅隆大学(CMU)元学习和元强化学习课程 | Elements of Meta-Learning
2021-03-07 00:28
标签:can multitask change code chm nts -o init sdn Introduction & overview of the key methods and developments. 原文链接: When is standard machine learning not enough? What is meta-learning? A Toy Example: Few-shot Image Classification Other (practical) Examples of Few-shot Learning Model-agnostic Meta-learning (MAML) 与模型无关的元学习 Does MAML Work? MAML from a Probabilistic Standpoint One More Example: One-shot Imitation Learning 模仿学习 Prototype-based Meta-learning Rapid Learning or Feature Reuse 特征重用 Drawing parallels between meta-learning and GPs Recall Gaussian Processes (GPs): 高斯过程 Conditional Neural Processes 条件神经过程 On software packages for meta-learning Recall the definition of learning-to-learn Meta-learning for RL On-policy RL: Quick Recap 符合策略的RL:快速回顾 On-policy Meta-RL: MAML (again!) Key points: Adaptation in nonstationary environments 不稳定环境 Continuous adaptation setup: Treat policy parameters, tasks, and all trajectories as random variables RoboSumo: a multiagent competitive env Takeaways 卡耐基梅隆大学(CMU)元学习和元强化学习课程 | Elements of Meta-Learning 标签:can multitask change code chm nts -o init sdn 原文地址:https://www.cnblogs.com/joselynzhao/p/12892696.html
Goals for the lecture:
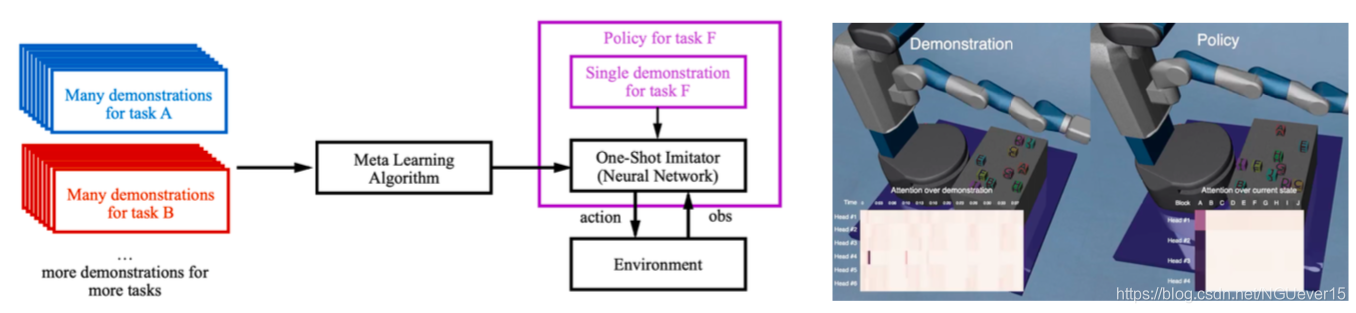
[Good starting point for you to start reading and understanding papers!]

@
Probabilistic Graphical Models | Elements of Meta-Learning
01 Intro to Meta-Learning

Motivation and some examples
Standard ML finally works for well-defined, stationary tasks.
But how about the complex dynamic world, heterogeneous data from people and the interactive robotic systems?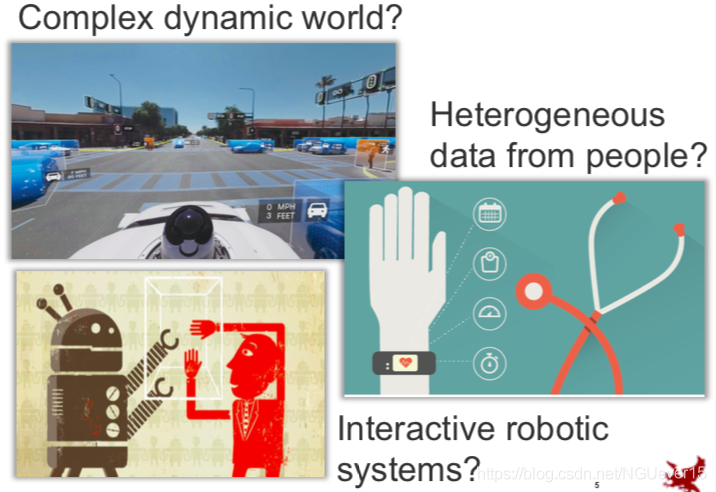
General formulation and probabilistic view
Standard learning: Given a distribution over examples (single task), learn a function that minimizes the loss: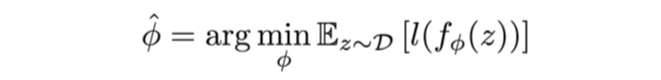
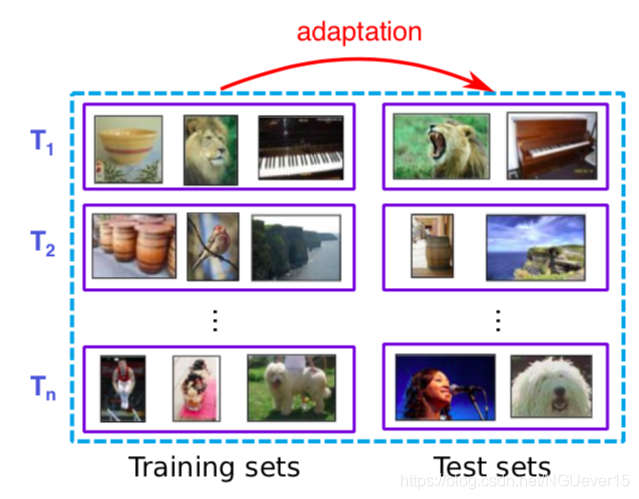
Learning-to-learn: Given a distribution over tasks, output an adaptation rule that can be used at test time to generalize from a task description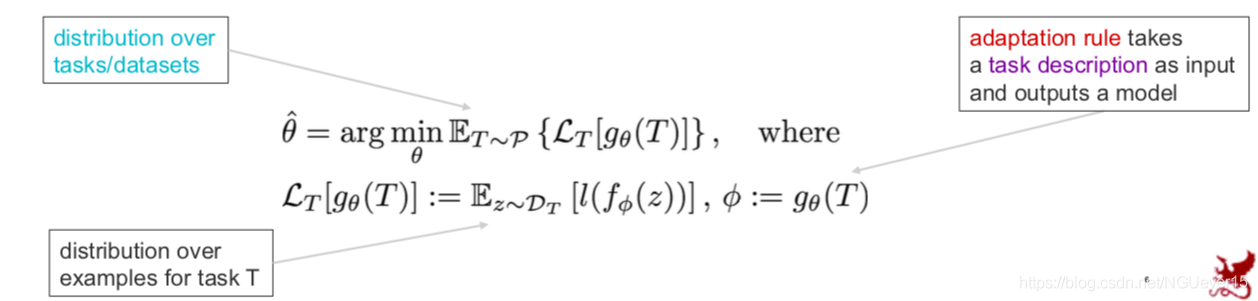

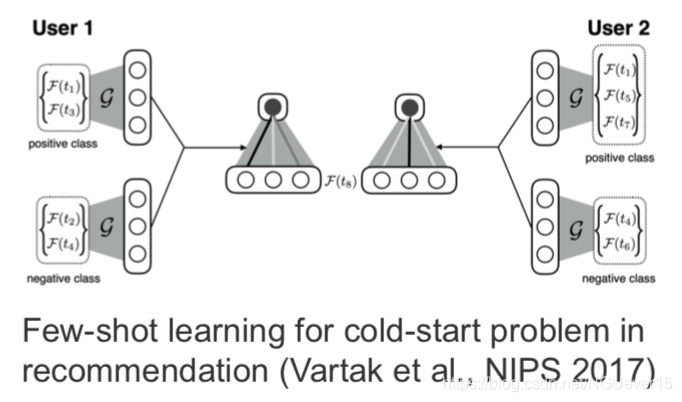
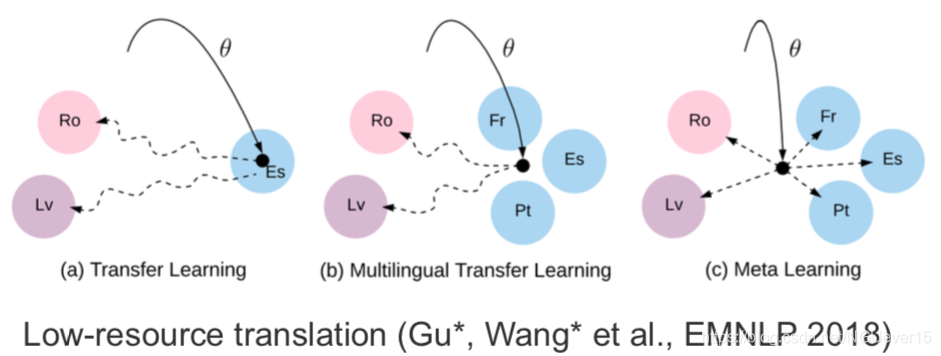
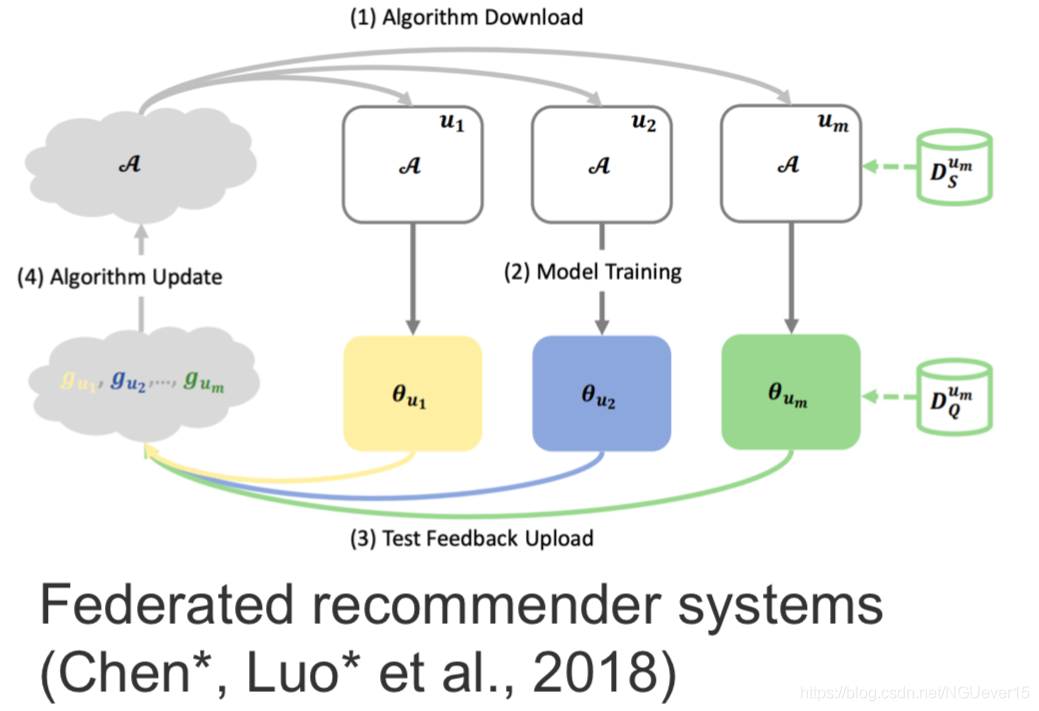

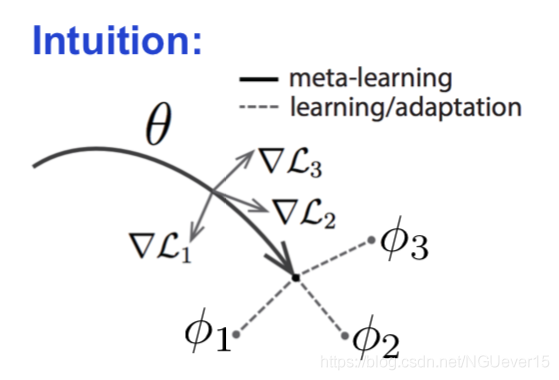
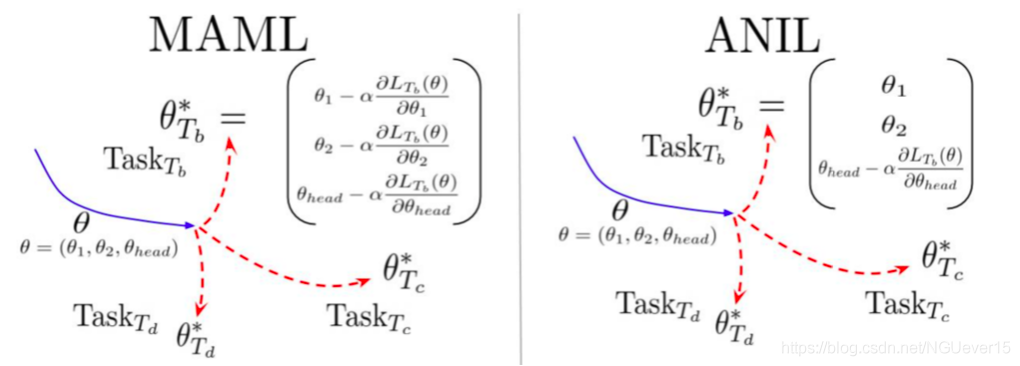
Gradient-based and other types of meta-learning
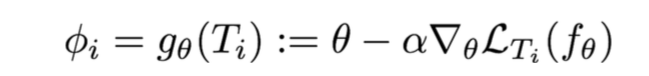
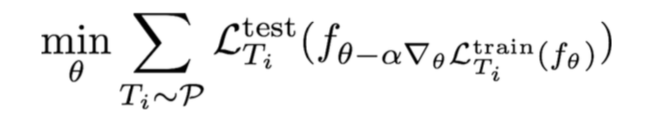
Training points: 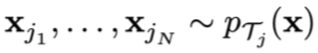
testing points: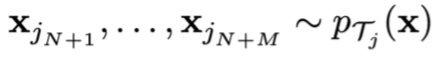
MAML with log-likelihood loss对数似然损失: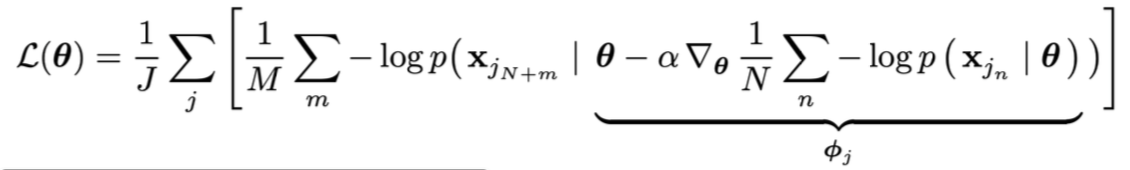
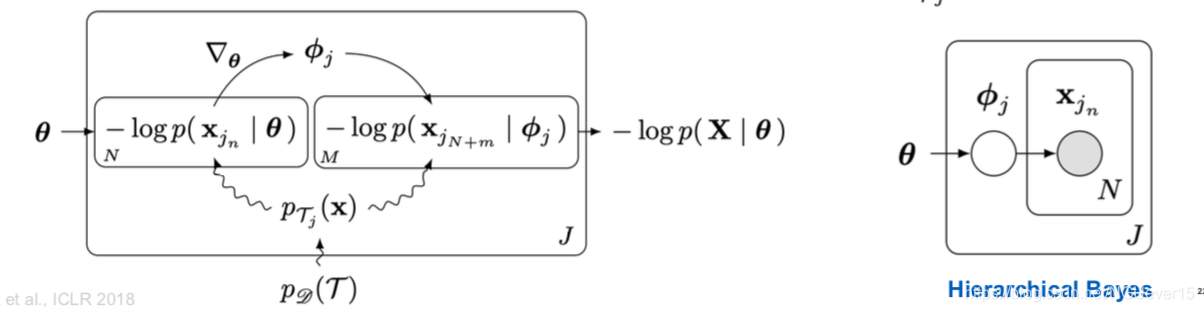
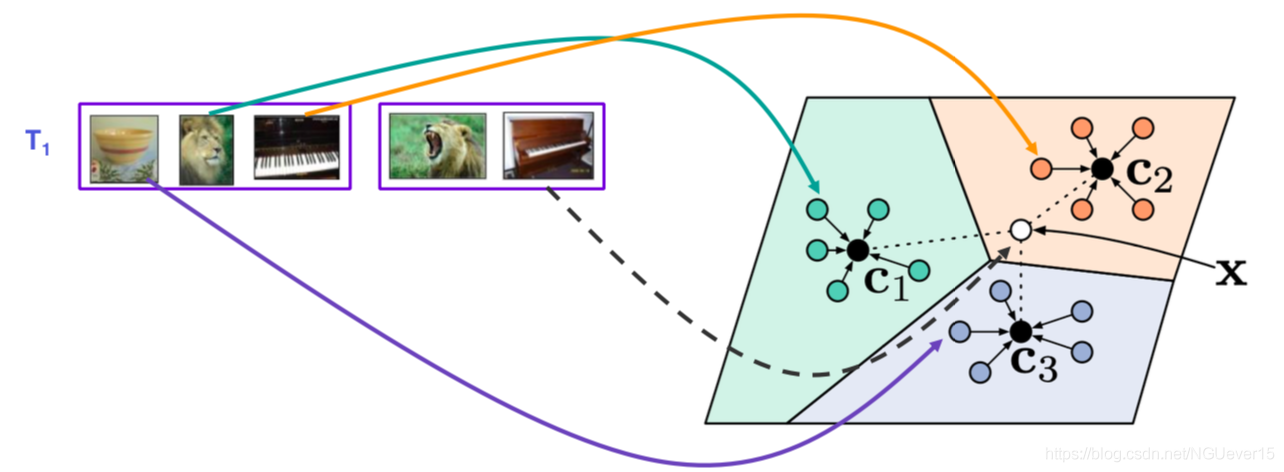
Prototypes: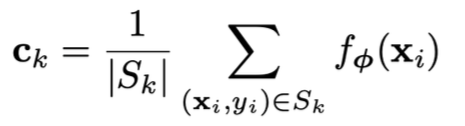
Predictive distribution: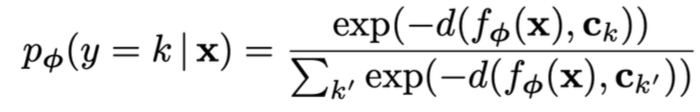
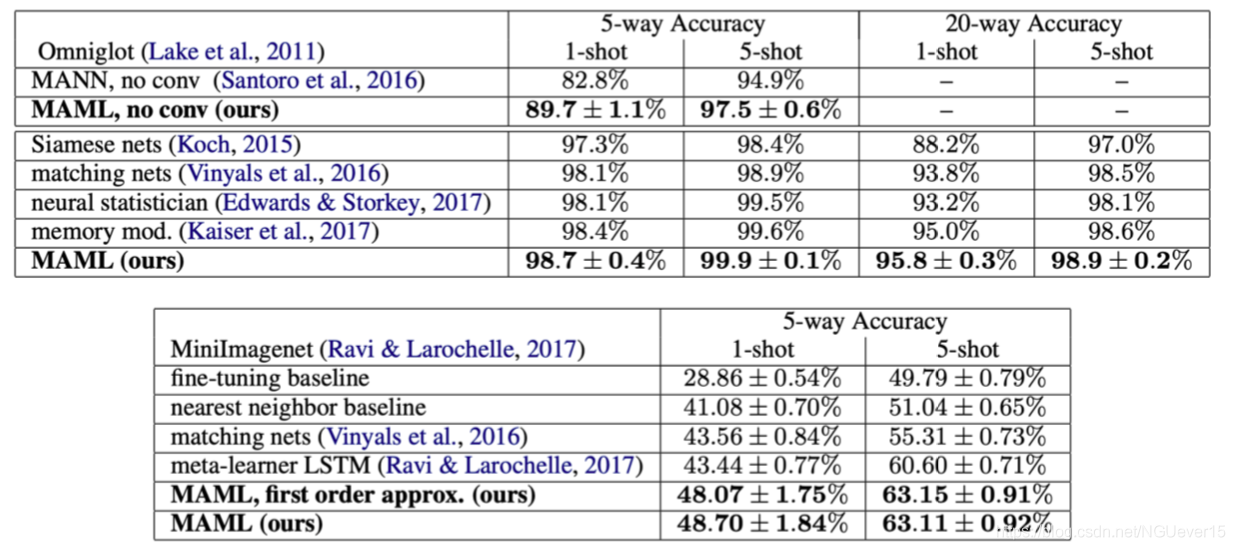
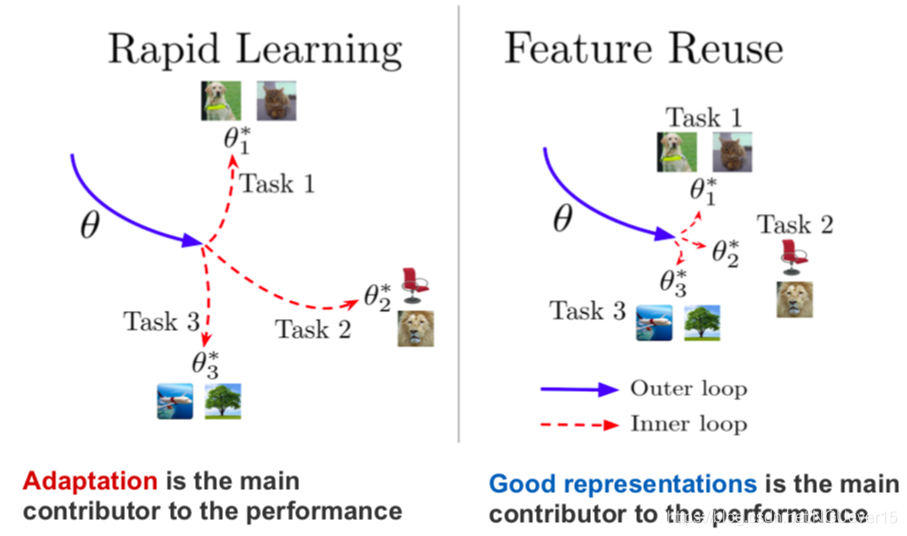
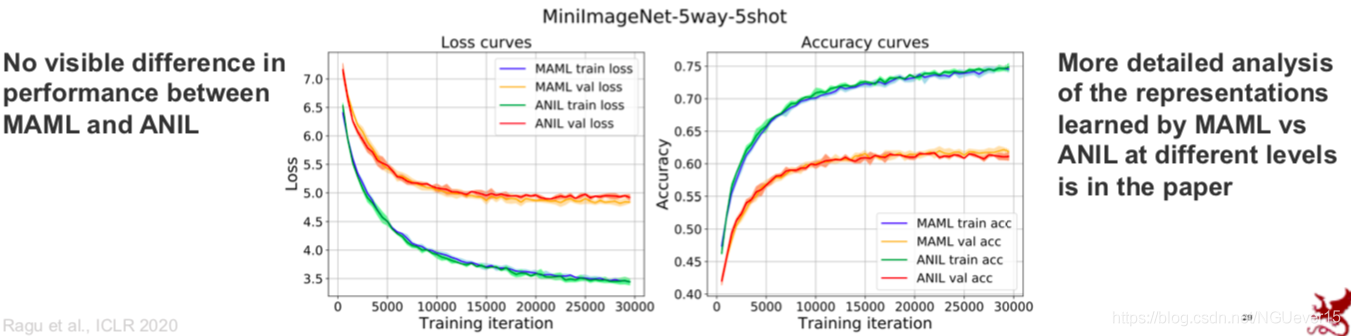
Does Prototype-based Meta-learning Work?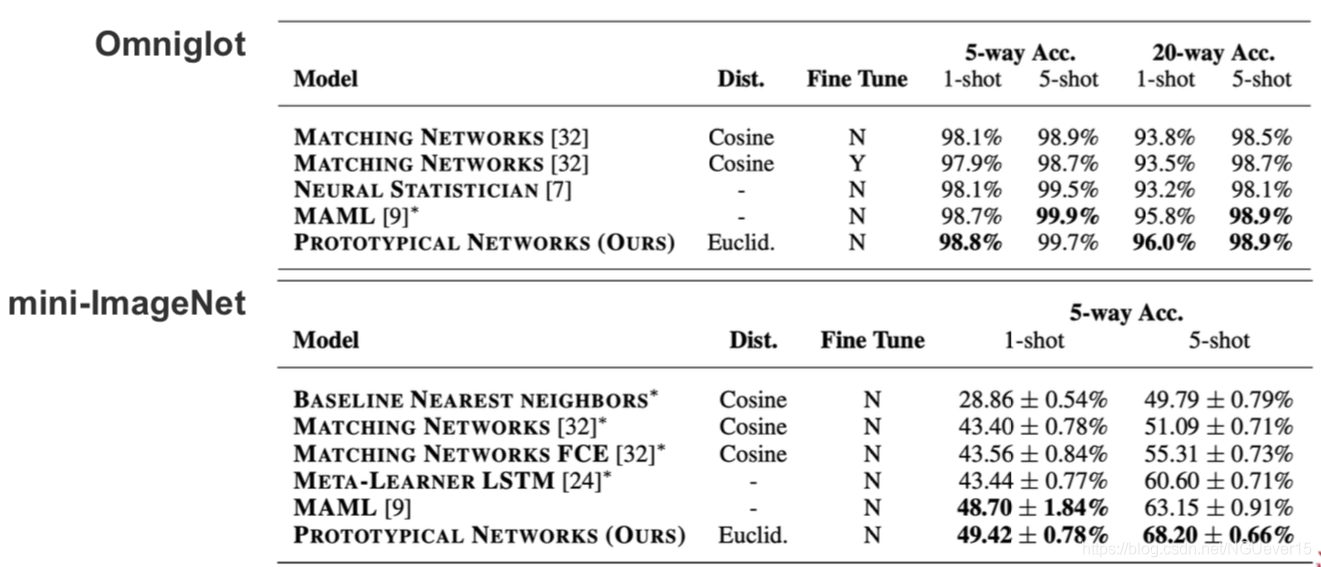

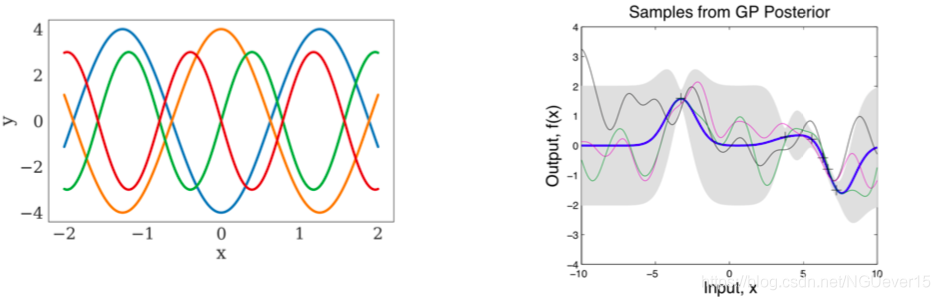
Neural processes and relation of meta-learning to GPs
In few-shot learning:
A lot of research code releases (code is fragile and sometimes broken)
A few notable libraries that implement a few specific methods:

Takeaways
02 Elements of Meta-RL
What is meta-RL and why does it make sense?
Standard learning: Given a distribution over examples (single task), learn a function that minimizes the loss: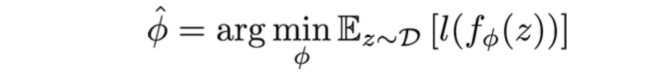
Learning-to-learn: Given a distribution over tasks, output an adaptation rule that can be used at test time to generalize from a task description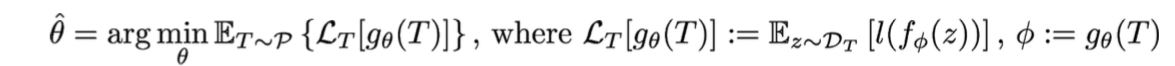
Meta reinforcement learning (RL): Given a distribution over environments, train a policy update rule that can solve new environments given only limited or no initial experience.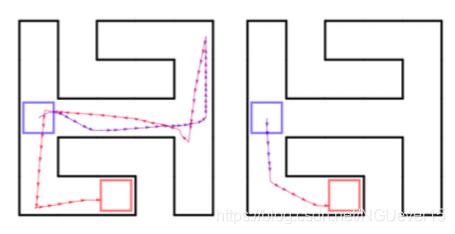
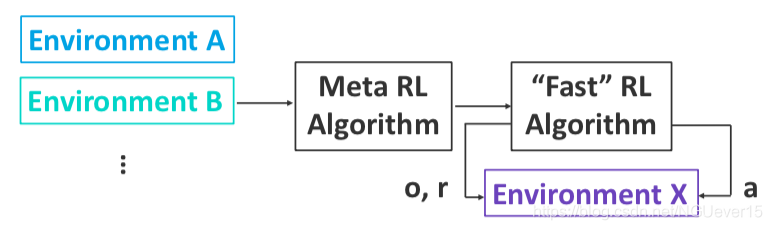
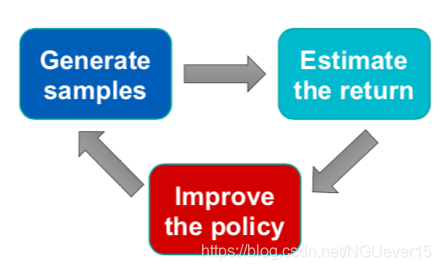
On-policy and off-policy meta-RL
REINFORCE algorithm: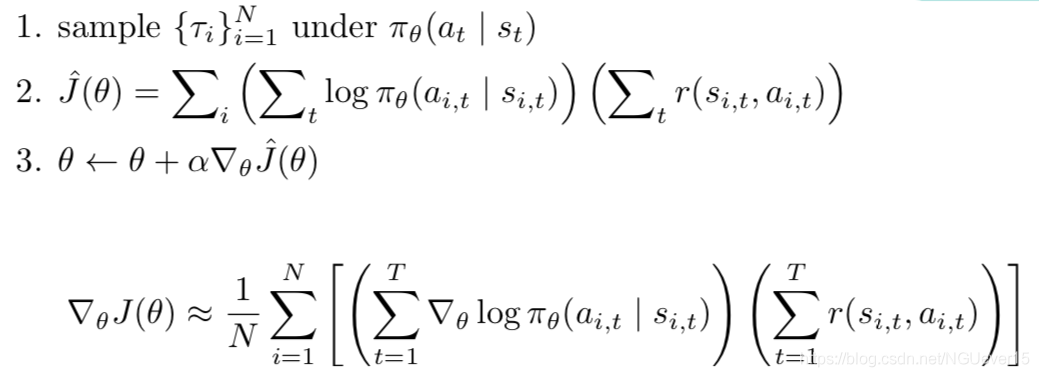
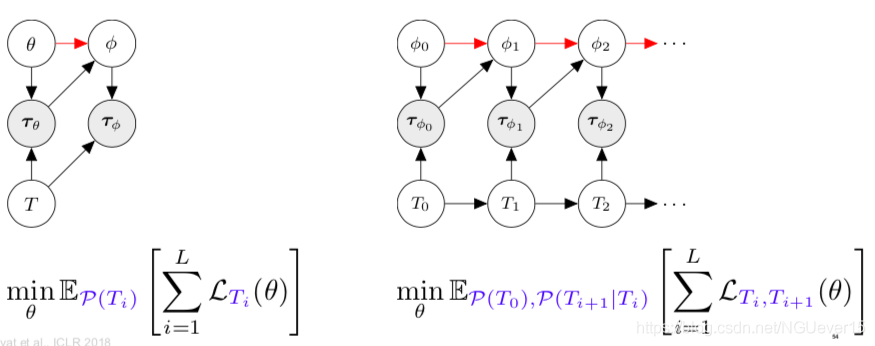
Adaptation as Inference 适应推理
Treat policy parameters, tasks, and all trajectories as random variables随机变量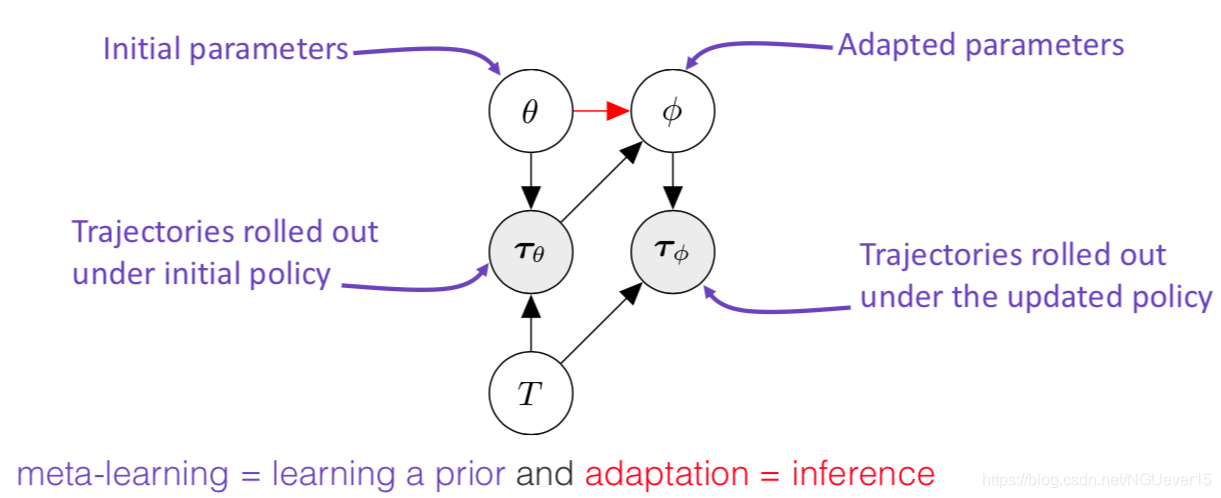
meta-learning = learning a prior and adaptation = inference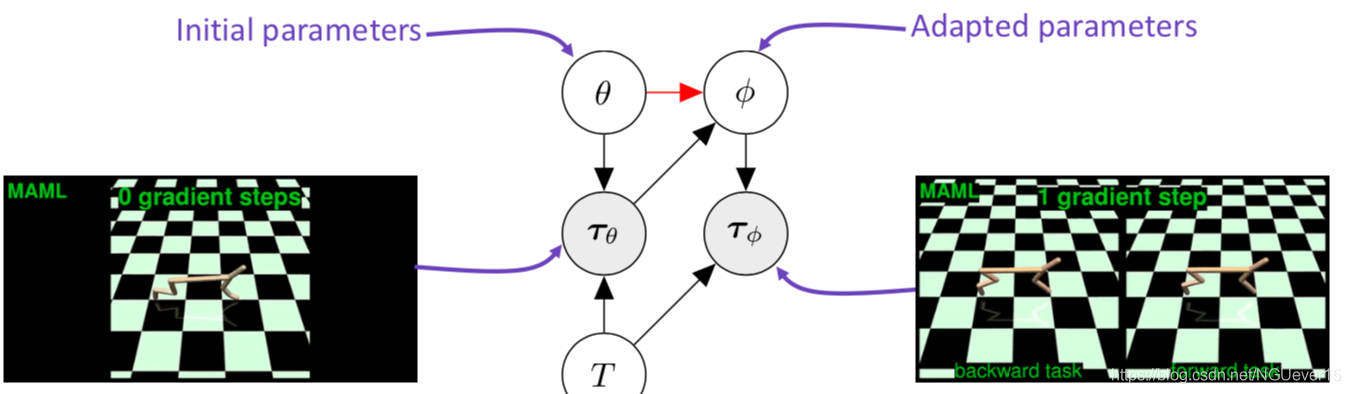
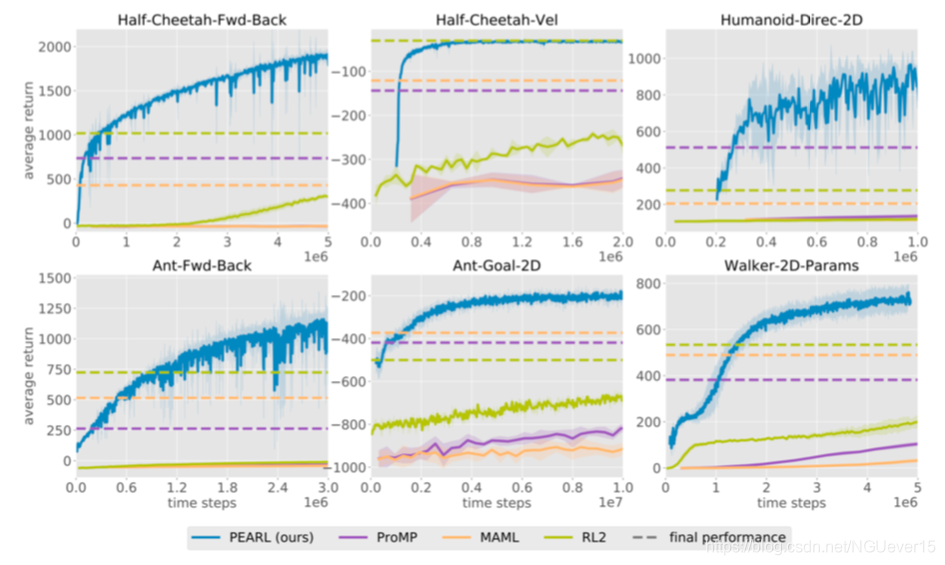
Off-policy meta-RL: PEARL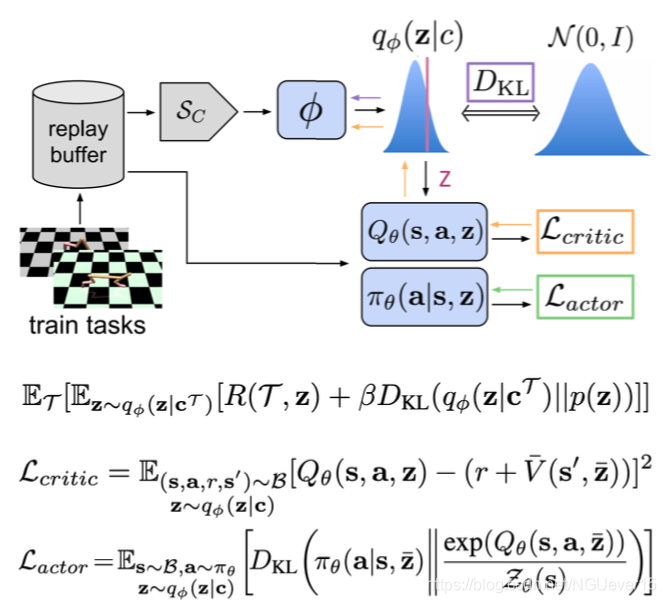
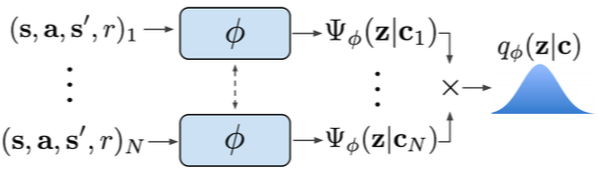
Classical few-shot learning setup:
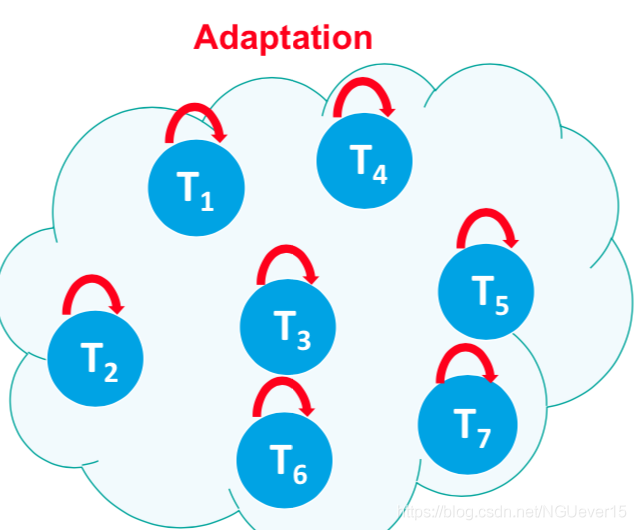
Example: adaptation to a learning opponent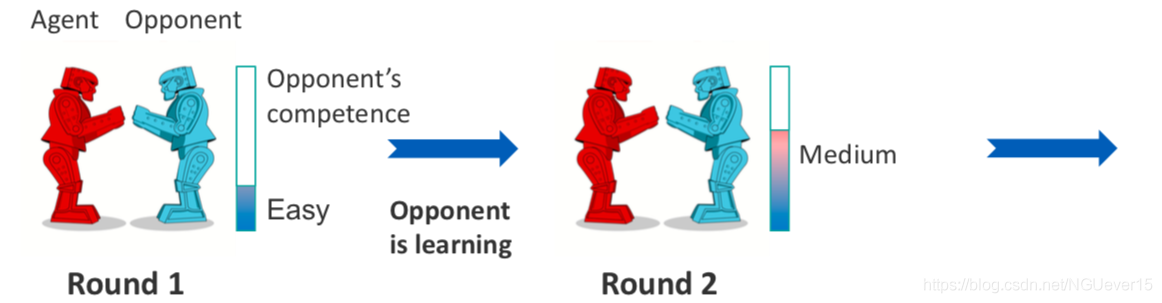 Each new round is a new task. Nonstationary environment is a sequence of tasks.
Each new round is a new task. Nonstationary environment is a sequence of tasks.
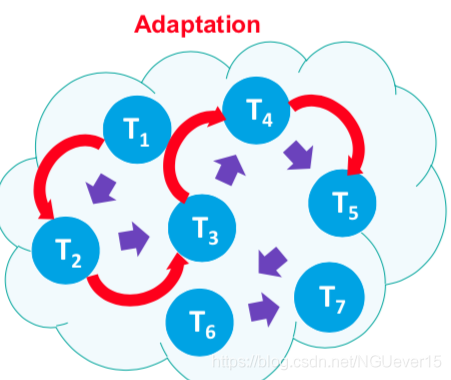
Continuous adaptation
an agent competes vs. an opponent, the opponent’s behavior changes over time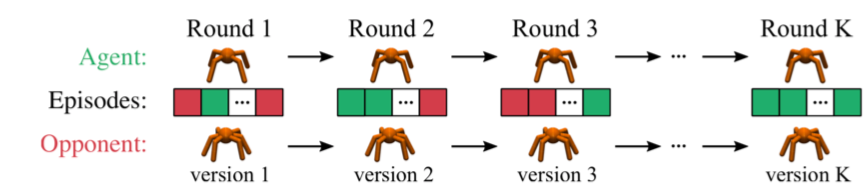
文章标题:卡耐基梅隆大学(CMU)元学习和元强化学习课程 | Elements of Meta-Learning
文章链接:http://soscw.com/index.php/essay/61094.html