第二章 - Java与协程
2021-05-04 13:29
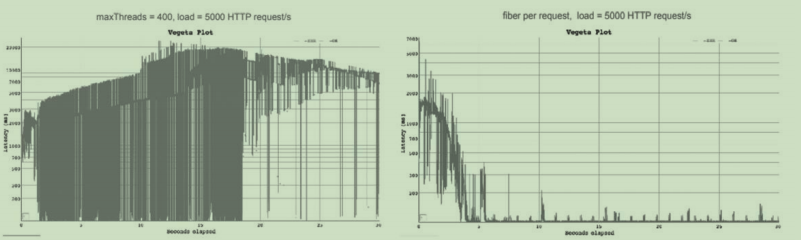
标签:src img 一个栈 成本高 阻塞 出栈 字节码 功能 官方 通过一个具体场景来解释目前Java线程面临的困境。今天对Web应用的服务要求,不论是在请求数量上还是在复杂度上,与十多年前相比已不可同日而语,这一方面是源于业务量的增长,另一方面来自于为了应对业务复杂化而不断进行的服务细分。现代B/S系统中一次对外部业务请求的响应,往往需要分布在不同机器上的大量服务共同协作来实现,这种服务细分的架构在减少单个服务复杂度、增加复用性的同时,也不可避免地增加了服务的数量,缩短了留给每个服务的响应时间。这要求每一个服务都必须在极短的时间内完成计算,这样组合多个服务的总耗时才不会太长;也要求每一个服务提供者都要能同时处理数量更庞大的请求,这样才不会出现请求由于某个服务被阻塞而出现等待。 Java目前的并发编程机制就与上述架构趋势产生了一些矛盾,1:1的内核线程模型是如今Java虚拟机线程实现的主流选择,但是这种映射到操作系统上的线程天然的缺陷是切换、调度成本高昂,系统能容纳的线程数量也很有限。以前处理一个请求可以允许花费很长时间在单体应用中,具有这种线程切换的成本也是无伤大雅的,但现在在每个请求本身的执行时间变得很短、数量变得很多的前提下,用户线程切换的开销甚至可能会接近用于计算本身的开销,这就会造成严重的浪费。 传统的Java Web服务器的线程池的容量通常在几十个到两百之间,当程序员把数以百万计的请求往线程池里面灌时,系统即使能处理得过来,但其中的切换损耗也是相当可观的。现实的需求在迫使Java去研究新的解决方案,同大家又开始怀念以前绿色线程的种种好处,绿色线程已随着Classic虚拟机的消失而被尘封到历史之中,它还会有重现天日的一天吗? 总结: 下来就是 java线程使用的是轻量级进程(使用的是系统原生线程, 后面都叫LWP吧), 这种LWP对于系统来说开销很大, 比如: 用户态到内核态的切换代价大; 线程的调度代价大; 系统可容纳的LWP也是有限的, 而现在我们追求的是微服务拆分, 通常一次客户请求需要用到多个微服务的服务组合到一起完成一次请求, 这样就要求我们的每个服务效率要很快, 但是LWP无法做到这点, 这这样的话, 只能找回绿色线程(用户线程)了吗?(绿色线程 jdk1.2 版本使用的线程实现方式) 不要以为系统调用(切换, 或者叫中断)的不太影响效率, 用户线程切换到内核线程的过程中, 用户线程需要保存用户线程切换的上下文数据, 然后还需要把寄存器, 内存分页等恢复到内核线程中, 这样内核线程才能够获取到充足的资料, 这样内核线程才能够重新激活, 这种保护和恢复现场的操作免不了涉及各种寄存器, 缓存的来回拷贝, 这可不是什么轻量级操作 但是如果使用用户线程就能避免掉这些么??? 其实不然, 但是如果使用了用户线程, 上面这些过程不就由我们控制了么???这样我们就能够使用我们的方法来减少这些开销 从dos时代开始用户就自发的模拟出多线程, 自己保护和恢复场景的工作模式, 大致就是在内存中找出一个栈结构, 模仿调用栈, 只要线程压栈和出栈的过程遵循规则, 并且这块内存不被破坏, 这样就成功模拟出了多线程, 到后来操作系统出现了多线程了, 这种模拟多线程的方式变少了, 但是还未消失, 以用户线程的形式继续存在, 由于最初多数的用户线程是被设计成协同式调度(Cooperative Scheduling)的,所以它有了一个别名——“协程”(Coroutine)。又由于这时候的协程会完整地做调用栈的保护、恢复工作,所以今天也被称为“有栈协程”(Stackfull Coroutine),起这样的名字是为了便于跟后来的“无栈协程”(Stackless Coroutine)区分开(无栈协程本质上是一种有限状态机,状态保存在闭包里,自然比有栈协程恢复调用栈要轻量得多,但功能也相对更有限)。 协程的优势主要在于它比LWP要轻的多, 在64位Linux上HotSpot的线程栈容量默认是1MB,此外内核数据结构(Kernel Data Structures)还会额外消耗16KB内存, 而一个协程的栈通常在几百个字节到几KB之间,所以Java虚拟机里线程池容量达到两百就已经不算小了,而很多支持协程的应用中,同时并存的协程数量可数以十万计 协程当然也有它的局限,需要在应用层面实现的内容(调用栈、调度器这些)特别多, 除此之外,协程在最初,甚至在今天很多语言和框架中会被设计成协同式调度,这样在语言运行平台或者框架上的调度器就可以做得非常简单, 但是这种方法存在很严重的问题, 详解前面的协同式调度 并且具体到Java语言,还会有一些别的限制,譬如HotSpot这样的虚拟机,Java调用栈跟本地调用栈是做在一起的。如果在协程中调用了本地方法,还能否正常切换协程而不影响整个线程?另外,如果协程中遇传统的线程同步措施会怎样?譬如Kotlin提供的协程实现,一旦遭遇synchronize关键字,那挂起来的仍将是整个线程 对于有栈协程,有一种特例实现名为纤程(Fiber),这个词最早是来自微软公司,后来微软还推出过系统层面的纤程包来方便应用做现场保存、恢复和纤程调度。OpenJDK在2018年创建了Loom项目,这是Java用来应对本节开篇所列场景的官方解决方案,根据目前公开的信息,如无意外,日后该项目为Java语言引入的、与现在线程模型平行的新并发编程机制中应该也会采用“纤程”这个名字,不过这显然跟微软是没有任何关系的。从Oracle官方对“什么是纤程”的解释里可以看出,它就是一种典型的有栈协程 Loom项目背后的意图是重新提供对用户线程的支持,但与过去的绿色线程不同,这些新功能不是为了取代当前基于操作系统的线程实现,而是会有两个并发编程模型在Java虚拟机中并存,可以在程序中同时使用。新模型有意地保持了与目前线程模型相似的API设计,它们甚至可以拥有一个共同的基类,这样现有的代码就不需要为了使用纤程而进行过多改动,甚至不需要知道背后采用了哪个并发编程模型。Loom团队在JVMLS 2018大会上公布了他们对Jetty基于纤程改造后的测试结果,同样在5000QPS的压力下,以容量为400的线程池的传统模式和每个请求配以一个纤程的新并发处理模式进行对比,前者的请求响应延迟在10000至20000毫秒之间,而后者的延迟普遍在200毫秒以下,具体结果如图 在新并发模型下,一段使用纤程并发的代码会被分为两部分——执行过程(Continuation)和调度器(Scheduler)。执行过程主要用于维护执行现场,保护、恢复上下文状态,而调度器则负责编排所有要执行的代码的顺序。将调度程序与执行过程分离的好处是,用户可以选择自行控制其中的一个或者多个,而且Java中现有的调度器也可以被直接重用。事实上,Loom中默认的调度器就是原来已存在的用于任务分解的Fork/Join池(JDK 7中加入的ForkJoinPool)。 Loom项目目前仍然在进行当中,还没有明确的发布日期,上面笔者介绍的内容日后都有被改动的可能。如果读者现在就想尝试协程,那可以在项目中使用Quasar协程库 如同JDK 5把Doug Lea的dl.util.concurrent项目引入,成为java.util.concurrent包,JDK 9时把Attila Szegedi的dynalink项目引入,成为jdk.dynalink模块。Loom项目的领导者Ron Pressler就是Quasar的作者 第二章 - Java与协程 标签:src img 一个栈 成本高 阻塞 出栈 字节码 功能 官方 原文地址:https://www.cnblogs.com/bangiao/p/13195652.htmlJava与协程
内核线程的局限
协程的复苏
协程的优势
Java的解决方案

[1],这是一个不依赖Java虚拟机的独立实现的协程库。不依赖虚拟机来实现协程是完全可能的,Kotlin语言的协程就已经证明了这一点。Quasar的实现原理是字节码注入,在字节码层面对当前被调用函数中的所有局部变量进行保存和恢复。这种不依赖Java虚拟机的现场保护虽然能够工作,但很影响性能,对即时编译器的干扰也非常大,而且必须要求用户手动标注每一个函数是否会在协程上下文被调用,这些都是未来Loom项目要
解决的问题。
下一篇:第七章 - 线程池应用